はじめてローカル LLM を触ってみる。
あとから見つけたのだが、今回やっていることとほぼ同じ内容が下記の記事で紹介されていた。
- Zed × Gemma 4 × Ollama — 環境構築作戦 | iret.media
- https://iret.media/194130
セットアップ:ツールやモデルのインストール #
LLM のツール:Ollama(オラマ) #
まず、LLM を動かすためにはツールが必要。ツールは様々あるが、個人で手軽に使えるものだと下記3つあたりが定番の様子。
- Llama.cpp(ラマ・シーピーピー): https://github.com/ggml-org/llama.cpp
- Ollama(オラマ): https://ollama.com/
- LM Studio(エルエム・スタジオ): https://lmstudio.ai/
(薄いツール) Llama.cpp > Ollama > LM Studio (分厚いツール) という感じらしい。
Llama.cpp は、LLM を実行するためのエンジン。C++ で書かれている。Ollama や LM Studio は Llama.cpp を内包しつつ、さらに管理要機能などを追加したラッパーツール。
Ollama は CLI ツール。モデルを管理する機能がある。たとえば ollama pull コマンドでモデルをダウンロードできる。
LM Studio は GUI ツール。モデルの管理に加え、チャット形式での対話などができる。ChatGPT のようなインターフェースで使いたいならこれ。
処理速度は Llama.cpp をそのまま使った方が速いらしいが、初めてローカル LLM に触れるのならば、まずは Ollama または LM Studio からスタートするのが良さそう。
私が求めている機能としては Ollama で十分そうだったので、今回は Ollama を使ってみることにする。
Mac では Homebrew で Ollama をインストールできる。
https://formulae.brew.sh/formula/ollama
brew install ollamaLLM のモデル:Gemma(ジェマ) #
Ollama で使用できるモデルは、Ollama の HP から検索できる。
Gemma(ジェマ)は Google DeepMind が開発している LLM で、オープンソースで公開されているため、ローカルにダウンロードして動かすことができる。今回は Gemma 4 を使ってみる.
https://ollama.com/library/gemma4
一口に Gemma 4 といっても、様々バージョン(タグ)がある。
https://ollama.com/library/gemma4/tags
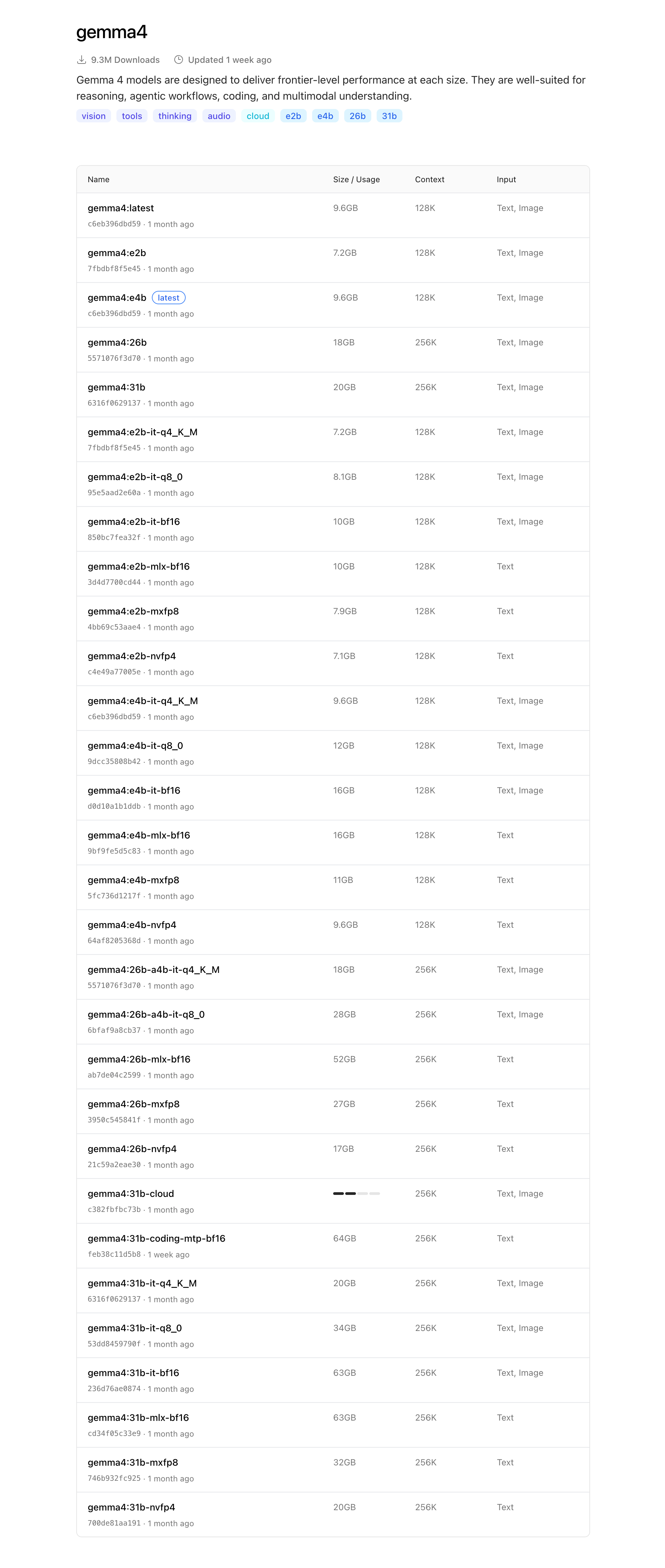
大別すると、4種類に分かれる。
Gemma 4 モデルには、E2B、E4B、31B、26B A4B の 4 つのパラメータサイズがあります。パラメータとビット数が多いモデル(高精度)は一般的に高性能ですが、処理サイクル、メモリコスト、消費電力の点で実行コストが高くなります。パラメータとビット数が少ないモデル(低精度)は機能が劣りますが、AI タスクには十分な場合があります。
ざっくりいうと、大きなモデルほど性能が高いが、要求されるリソース(メモリ等)も大きくなるため、自身の実行環境に合わせたモデルを選ぶ必要があるということ。
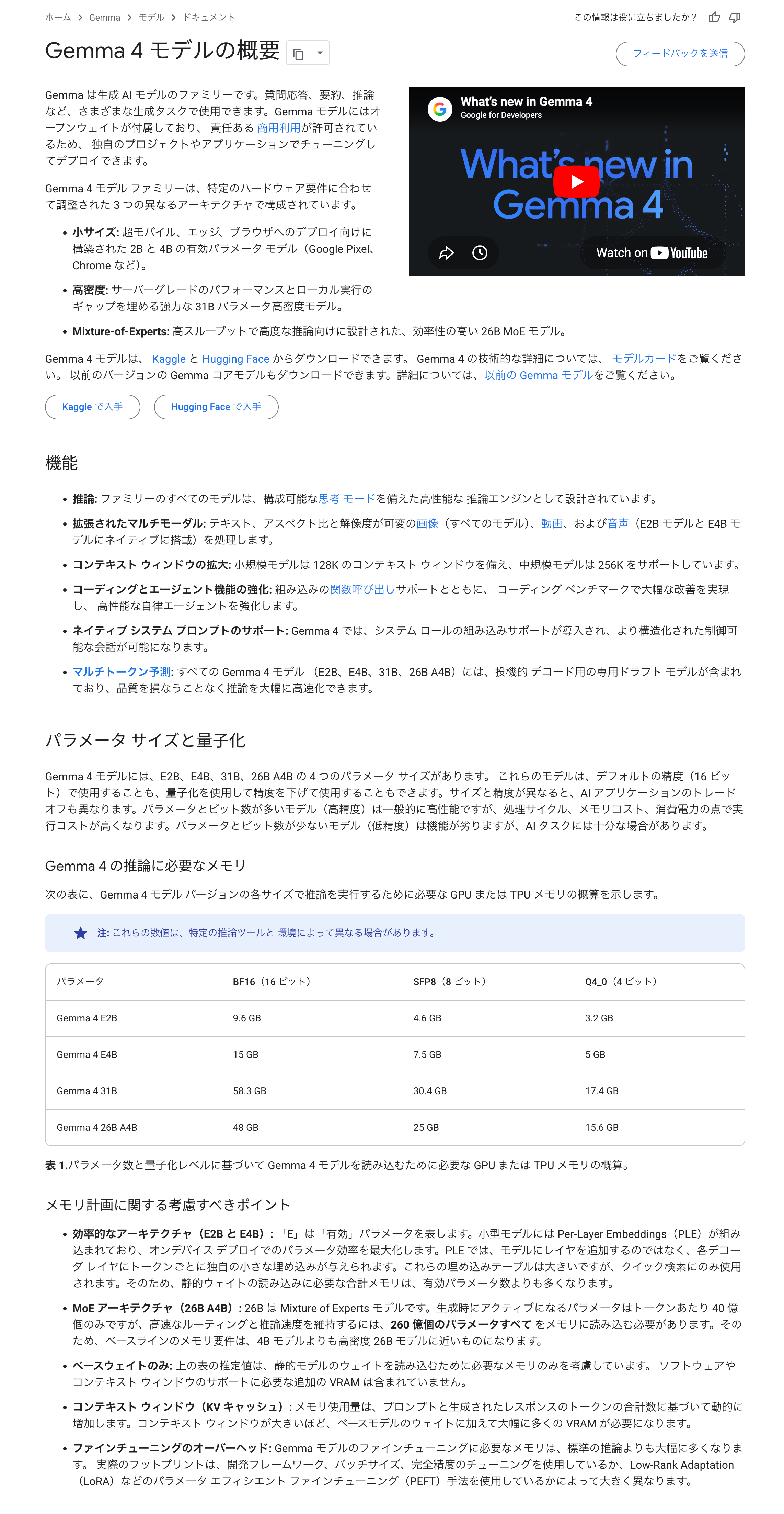
私の環境(MacBook Pro / Chip: M4 / Memory: 24GB)では、E4B がちょうど良さそうだったので、今回は gemma4:e4b タグのモデルを使ってみることにする。
ollama pull コマンドで、モデルをダウンロードすることができる。
ollama pull gemma4:e4b
> pulling manifest
> pulling 4c27e0f5b5ad: 100% ▕██████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 9.6 GB
> pulling 7339fa418c9a: 100% ▕██████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 11 KB
> pulling 56380ca2ab89: 100% ▕██████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 42 B
> pulling f0988ff50a24: 100% ▕██████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 473 B
> verifying sha256 digest
> writing manifest
> successollama list コマンドで、ダウンロード済みのモデル一覧を確認できる。
ollama list
> NAME ID SIZE MODIFIED
> gemma4:e4b c6eb396dbd59 9.6 GB 30 seconds ago実行:LLM を動かしてみる #
チャットしてみる #
ollama run コマンドで、モデルを実行することができる。
ollama run gemma4:e4b
>>> Send a message (/? for help)あいさつしてみる。
>>> こんにちは!
こんにちは!😊
何かお手伝いできることはありますか?お気軽にお声がけくださいね。Gemma が動いていることが確認できた。
コードを作らせてみる #
次にエディタの Zed と連携してみる。
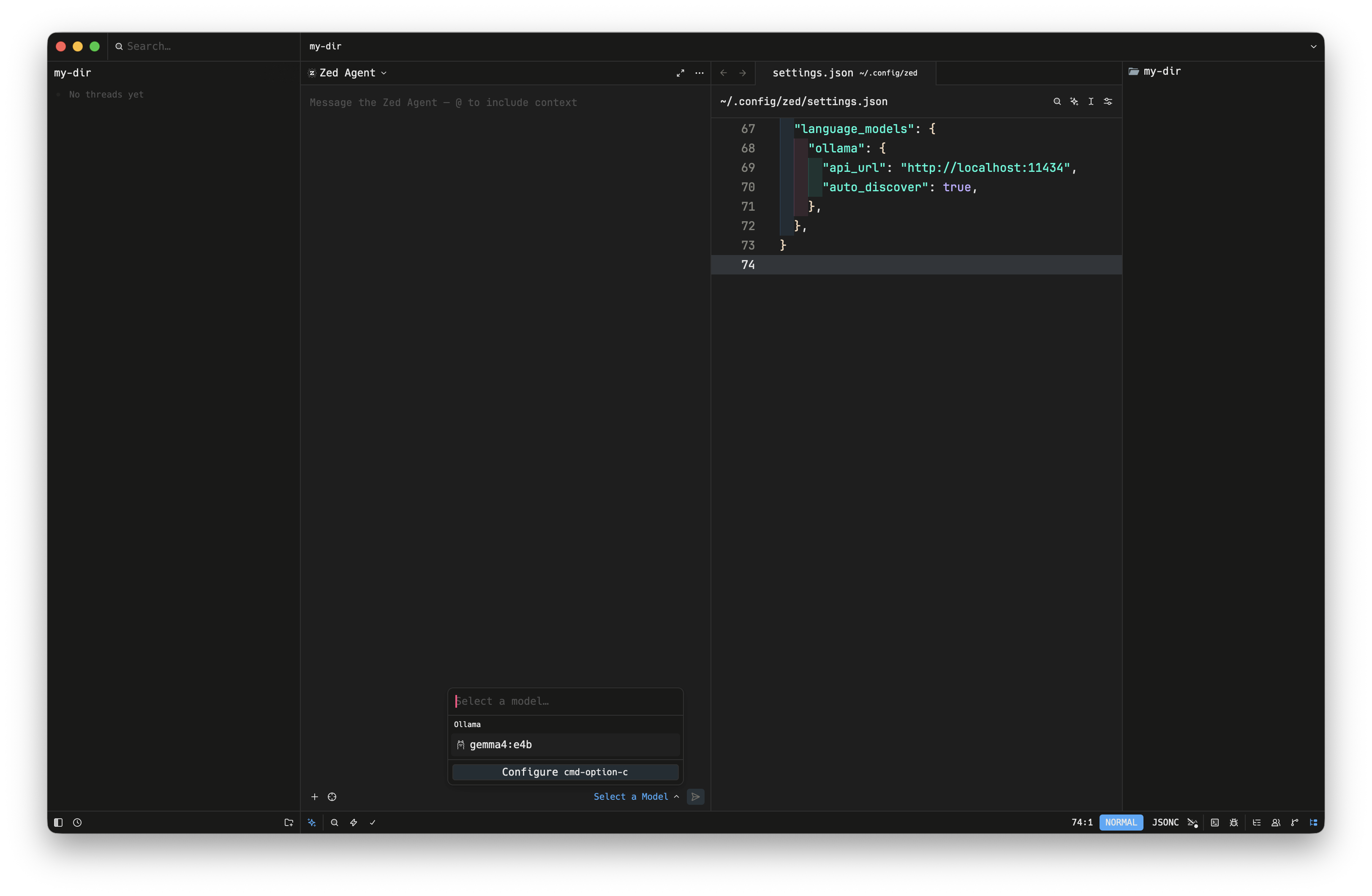
Zed の settings.json に language_models ブロックを追加、Ollama の API URL を指定する。
{
// ... 省略
//
"language_models": {
"ollama": {
"api_url": "http://localhost:11434",
"auto_discover": true
}
}
}Agent パネルからモデルを選択しようとすると gemma4 が選択できるようになっている。
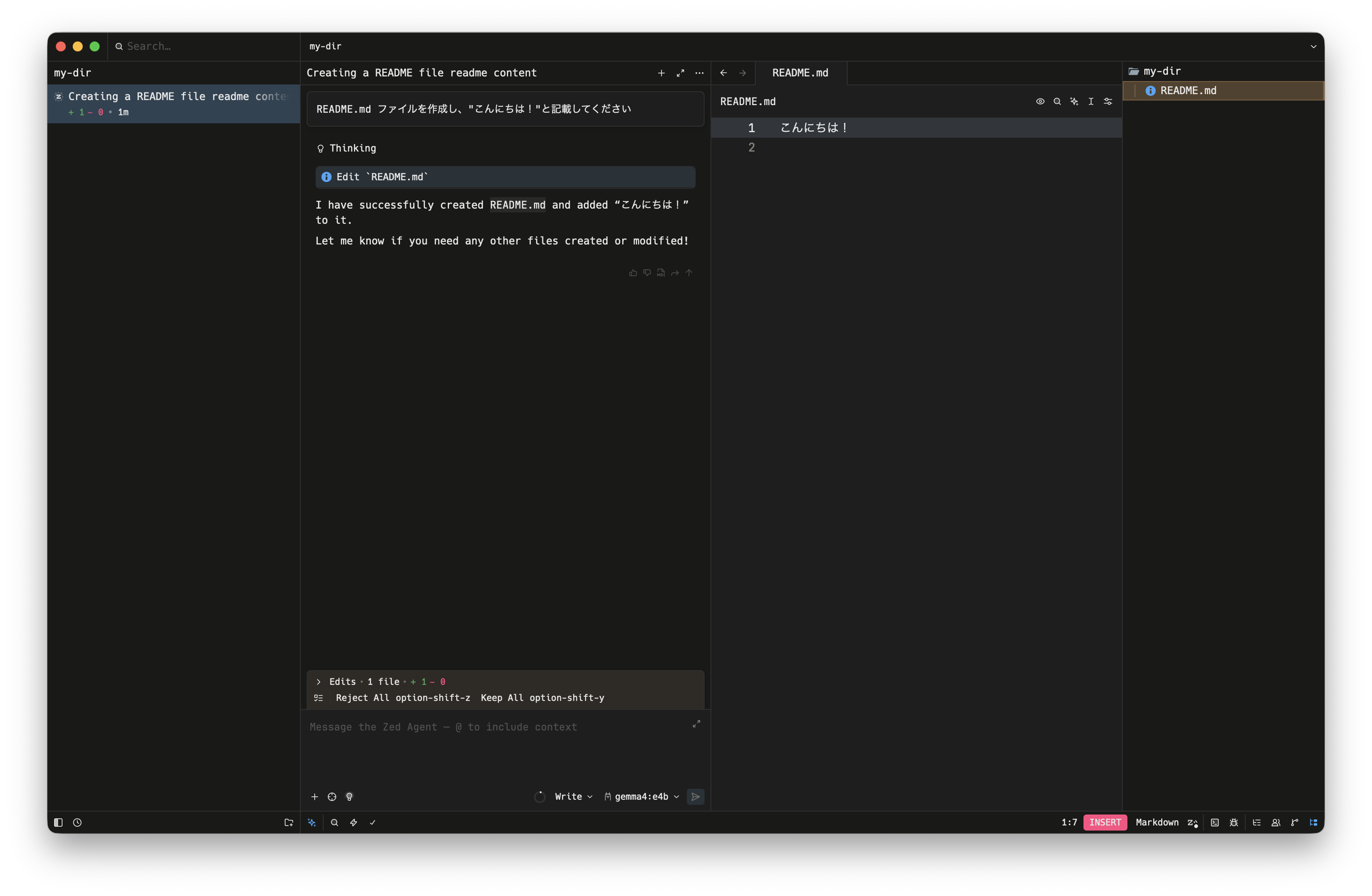
指示を出してみるとちゃんとコードを生成してくれた。
補足:モデルの探し方 #
LLM Stats(https://llm-stats.com/)というサイトで、様々なモデルの性能が比較されている。
特に、オープンソース LLM については、下記のページで性能比較されている。
- Open LLM Leaderboard - Compare Open Source LLM Rankings
- https://llm-stats.com/leaderboards/open-llm-leaderboard
身近な人が、Qwen 3.6 がとても性能が良いと話していたので、次はそれを試してみたい。