
以下の本を読んだ。記憶しておきたいところについてメモを残しておく。
- Clean Architecture - 達人に学ぶソフトウェアの構造と設計
- https://www.kadokawa.co.jp/product/301806000678/
本書といえば以下の図で有名な本。
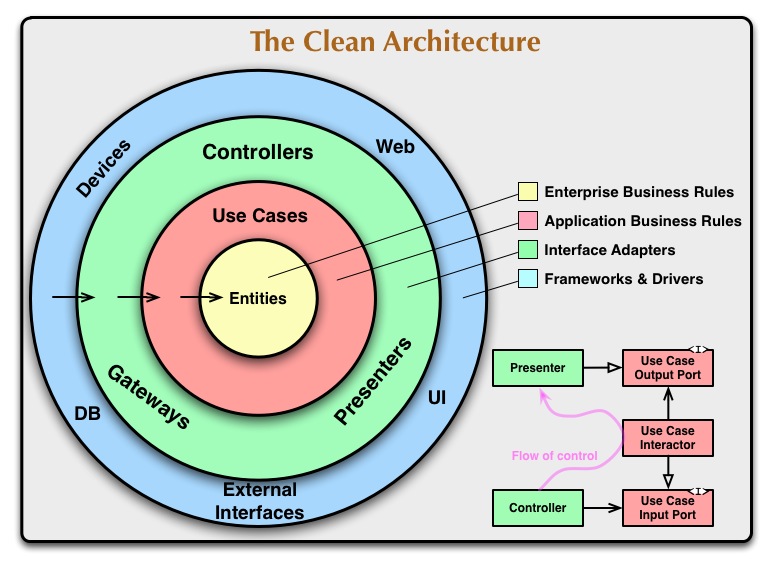
引用元:https://blog.cleancoder.com/uncle-bob/2012/08/13/the-clean-architecture.html
しかし実は本書の容量約 300 ページほどに対して、こちらの図が登場するのはちょうど 200 ページ目。
本書は冒頭、優れた設計の定義からはじまって、SOLID 原則の章へと続く。その他いくつかの原則の章を経たのちに上記画像のクリーンアーキテクチャの章へと進む。このようにミクロからマクロへと設計の焦点を移していきながら、各焦点において適用できる優れたルール・ベストプラクティスをまとめたものが本書である。上記の図があまりにも有名になっているが、実は本書においてはトピックの1つに過ぎない。
本書の序文は次のように締め括られている。
「どんな種類のシステムでもソフトウェアアーキテクチャのルールは同じ。ソフトウェアアーキテクチャのルールとは、プログラムの構成要素をどのように組み立てるかのルールである。構成要素は普遍的で変わらないのだから、それらを組み立てるルールもまた、普遍的で変わらないのである。若いプログラマは「そんなわけがない」と言うかもしれない。昔は昔、今は今、過去のルールが今でも通用するわけがないと思うのだろう。もしそう考えているのなら、残念ながら間違っている。ルールは何も変わっていない。言語やフレームワークやパラダイムがまったく新しいものに変わったところで、ルール自体は Alan Turing が最初のマシンコードを書いた 1946 年と同じままだ。でも、ひとつだけ変わったことがある。かつての我々は、そのルールがどんなものか知らなかった。そのせいで、何度となくルールを破ってきた。今は違う。半世紀の経験を経て、我々はようやくルールを掴んだ。時代を超越した普遍のルールたち。それこそが本書だ。」
第 1 部:イントロダクション #
第 1 章:設計とアーキテクチャ #
目的は? #
優れたソフトウェアの設計の目的とは何か?
「ソフトウェアアーキテクチャの目的は、求められるシステムを構築・保守するために必要な人材を最小限に抑えることである。」
設計の品質は、顧客のニーズを満たすために必要な労力で計測できる。必要な労力が少なく、システムのライフタイム全体で低く保たれているならば、その設計は優れている。逆に、リリースごとに労力が増えるなら、その設計は優れていない。
第 2 部:構成要素から始めよ - プログラミングパラダイム #
第 5 章:オブジェクト指向プログラミング #
優れたアーキテクチャの基本となるのは「オブジェクト指向設計」の原則の理解と適用である。だが、オブジェクト指向(OO: Object Oriented)とは何だろうか?
ひとつの答えに「データと関数の組み合わせ」がある。これはよく引き合いに出されるものだが、満足できない答えである。o.f() と f(o) が別物であるかのように扱われているからだ。バカバカしい。
もうひとつのよくある答えに「現実の世界をモデル化する方法」がある。言い訳がましい答えだ。「現実の世界をモデル化」とは、何を意味しているのだろうか?どうしてそんなことをしたいと思うのだろうか?おそらくこれは、OO を使えばソフトウェアと現実世界が近くなるので、ソフトウェアのことを理解しやすくなる、といったことを意図しているのだろう。あまりにも言い訳がましい答えだが、そもそも定義が雑すぎる。結局、OO とは何なのかを明らかにしていない。
あるいは、カプセル化、継承、ポリモーフィズムという 3 つの魔法の言葉で、OO の性質を説明しようとする人もいる。おそらくこういう人たちは「OO はこれら 3 つの適切な混合物である」とか「OO 言語はこれら 3 つをサポートするべきだ」などと言いたいのだろう。
「OO とは何か?」この質問には、多くの意見と多くの答えがある。だが、ソフトウェアアーキテクトにとって、その答えは明らかだ。OO とは「ポリモーフィズムを使用することで、システムにあるすべてのソースコードの依存関係を絶対的に制御する能力」である。
OO 言語が安全で便利なポリモーフィズムを提供しているというのは、ソースコードの依存関係は(たとえどこであっても)逆転できることを意味する。ソースコードにあるすべての依存関係は、インターフェイスを挿入することで逆転可能である。
このアプローチを使うことで、OO 言語で書かれたシステムに取り組んでいるソフトウェアアーキテクトは、システムにあるすべてのソースコードの依存関係の方向を絶対的に制御できる。依存関係を制御の流れに合わせる必要はない。どのモジュールが呼び出しを行い、どのモジュールが呼び出されようとも、ソフトウェアアーキテクトはソースコードの依存関係をどの方向にも向けることができる。
これはパワーだ!これが OO の提供するパワーである。これこそが本当の OO だ。少なくともアーキテクトの観点からはそう言える。
第 3 部:設計の原則 #
よくできたソフトウェアシステムは、クリーンなコードを書くことから始まる。レンガの出来が悪ければ、その建築は優れたものにはならない。一方、たとえよくできたレンガを使っても、ぐちゃぐちゃなものを作ってしまうことがあり得る。そこで登場するのが「SOLID 原則」だ。SOLID 原則は、関数やデータ構造をどのようにクラスに組み込むのか、そしてクラスの相互接続をどのようにするのかといったことを教えてくれる。ここでいるクラスとは、単にいくつかの機能やデータを取りまとめたものを指しているにすぎない。「クラス」と呼ぶかどうかは別として、どのようなソフトウェアシステムにもそのような仕組みはあるはずだ。SOLID 原則は、そうした仕組みに適用するものである。
- 単一責任の原則(SRP: Single Responsibility Principle)
- オープン・クローズドの原則(OCP: Open-Closed Principle)
- リスコフの置換原則(LSP: Liskov Substitution Principle)
- インターフェイス分離の原則(ISP: Interface Segregation Principle)
- 依存関係逆転の原則(DIP: Dependency Inversion Principle)
第 7 章:SRP - 単一責任の原則 #
SOLID 原則のなかで最も誤解されがちなのが「単一責任の原則」だろう。おそらくその原因は、名前があまりよくなかったことだ。この原則の名前を聞いたプログラマは「どのモジュールもたったひとつのことだけを行うべき」と受け取ってしまう。
確かにそのような原則も存在する。ひとつの関数はたったひとつのことだけを行うべきというものだ。巨大な関数にリファクタリングを施して、小さな関数に切り分けるときに使うのがこの原則である。ただ、これを用いるのは最下位のレベルだ。SOLID 原則の単一責任の原則とは別のものである。
かつて単一責任の原則は、以下のように語られてきた。
モジュールを変更する理由はたったひとつだけであるべきである。
ソフトウェアシステムに手を加えるのは、ユーザーやステークホルダーを満足させるためだ。この「ユーザーやステークホルダー」こそが、単一責任の原則が指す「変更する理由」である。つまり、この原則は以下のように言い換えられる。
モジュールはたったひとりのユーザーやステークホルダーに対して責務を負うべきである。
残念ながら「たったひとりのユーザーやステークホルダー」という表現は適切ではない。複数のユーザーやステークホルダーがシステムを同じように変更したいと考えることもある。ここでは、変更を望む人たちをひとまとめにしたグループとして扱いたい。このグループのことをアクターと呼ぶことにしよう。
これを踏まえると、最終的な単一責任の原則は以下のようになる。
モジュールはたったひとつのアクターに対して責務を負うべきである。
単一責任の原則を理解するには、この原則に違反している例を見るのが一番だ。
給与システムにおける Employee クラスだ。このクラスには、calculatePay()、reportHours()、save() の 3 つのメソッドがある。
このクラスは単一責任の原則に違反している。3 つのメソッドがそれぞれ別々のアクターに対する責務を負っているからだ。
- calculatePay() メソッドは、経理部門が規定する。報告先は CFO だ。
- reportHours() メソッドは、人事部門が規定して使用する。報告先は COO だ。
- save() メソッドは、データベース管理者が規定する。報告先は CTO だ。
これらのメソッドをひとつの Employee クラスに入れると、開発者はすべてのアクターを結合することになる。この結合が原因となり、CFO チームの何らかの操作が、COO チームの使うものに影響を及ぼしてしまうこともある。
単一責任の原則はアクターの異なるコードは分割するべきという原則だ。
第 8 章:OCP - オープン・クローズドの原則 #
ソフトウェアの構成要素は拡張に対しては開いていて、修正に対して閉じていなければならない。
言い換えれば、ソフトウェアの振る舞いは、既存の成果物を変更せず拡張できるようにすべきである、ということだ。
これこそが、我々がソフトウェアアーキテクトを学ぶ根本的な理由だ。ちょっとした拡張のために大量の書き換えが必要になるようなら、そのソフトウェアシステムのアーキテクトは大失敗への道を進んでいることになる。
ソフトウェア設計の研究者の多くは、オープン・クローズドの原則はクラスやモジュールを設計する際の指針となる原則だと考えている。だが、コンポーネントのレベルを考慮したとき、この原則はさらに重要なものとなる。
第 11 章:DIP - 依存関係逆転の原則 #
ソースコードの依存関係が(具象ではなく)抽象だけを参照しているもの。それが、最も柔軟なシステムである。これが「依存関係逆転の原則」の伝えようとしていることである。
Java のような静的型付け言語ならば、use や import や include で指定する参照先を、インターフェイスや抽象クラスなどの抽象宣言だけを含むソースモジュールに限定するということだ。具象に依存するべきではない。
このルールを絶対的なものとして守り続けるのは明らかに現実的ではない。ソフトウェアシステムは数多くの具象に依存しているからだ。たとえば、Java の String クラスは具象であり、これを抽象にするのは無理がある。ソースコードが具象の Java.lang.string に依存するのは避けられないし、避けるべきでもない。
String クラスは他のクラスに比べて非常に安定している。変更されることはほとんどないし、あったとしてもきちんとコントロールされている。プログラマやアーキテクトは、String の内容がコロコロ変わることなど心配しなくていい。
そのような理由から、依存関係逆転の原則を考えるときには OS やプラットフォームまわりは気にしないことが多い。変化しないとみなして構わないので、こうした具象への依存は許容することにしよう。
依存したくないのは、システム内の変化しやすい具象要素だ。開発中のモジュールや、頻繁に変更され続けているモジュールがその対象になる。
抽象インターフェイスの変更は、それに対応する具象実装の変更につながる。一方、具象実装を変更してもインターフェイスの変更が必要になることはあまりない。つまり、インターフェイスは実装よりも変化しにくいということだ。
優れたソフトウェア設計者やアーキテクトは、インターフェイスの変動性をできるだけ抑えようとする。新しい機能を実装するときにも、できる限りインターフェイスの変更なしで済ませられるようにする。これは、ソフトウェア設計の基本中の基本だ。
安定したソフトウェアアーキテクチャは、変化しやすい具象への依存を避け、安定した抽象インターフェイスに依存すべきである。
第 5 部:アーキテクチャ #
第 20 章:ビジネスルール #
アプリケーションをビジネスルールとプラグインに分割する場合、実際のビジネスルールがどのようなものかを把握しておいたほうがいいだろう。ビジネスルールにはいくつかの種類があることがわかる。
ビジネスルールとは、ビジネスマネーを生み出したり節約したりするルールや手続きのことだ。厳密に言えば、コンピュータで実装されているかどうかに関わらず、ビジネスマネーを生み出したり節約したりするルールのことだ。手動で実行されたとしても、お金を生み出したり節約したりすることはできる。
たとえば、銀行がローンに N% の利子を付けているとすると、それは銀行のお金を生むためのビジネスルールになる。利子をコンピュータで計算しようと、そろばんで計算しようと、まったく関係はない。
こうしたルールのことを最重要ビジネスルールと呼ぶ。ビジネスにとって欠かせないものであり、システムが自動化されていなくても存在するからだ。
最重要ビジネスルールには、いくつかのデータが必要になる。たとえば、ローンであれば、貸付金残高、金利、支払いスケジュールなどが必要になる。
こうしたデータのことを最重要ビジネスデータと呼ぶ。システムが自動化されていなくても存在するデータだからだ。
最重要ビジネスルールと最重要ビジネスデータは密接に結びついているため、オブジェクトの有力な候補になる。こうしたオブジェクトのことをエンティティと呼びたい。
エンティティ
エンティティとは、コンピュータシステムの内部にあるオブジェクトであり、最重要ビジネスデータを操作する最重要ビジネスルールをいくつか含んだものである。エンティティオブジェクトには、最重要ビジネスデータかそれらのデータへの簡単なアクセス手段が含まれる。エンティティのインターフェイスは、そうしたデータを操作する最重要ビジネスルールを実装した関数で構成されている。
こうしたクラスを作成するときは、ビジネスにとって不可欠な概念を実装するソフトウェアをまとめ、これから構築するシステムから切り離すようにする。つまり、ビジネスを表すものとして、エンティティのクラスを独立させるのである。エンティティは、データベース、ユーザーインターフェイス、サードパーティ製のフレームワークについて、何も気にする必要はない。システムがどのようなものであっても、データがどのように保存されていても、コンピュータがどのように配置されていても、エンティティはあらゆるシステムのビジネスに役立つ。エンティティはビジネスであり、それ以外の何者でもない。
ユースケース
ビジネスルールはエンティティほど純粋なものばかりではない。自動化されたシステムを定義・制限することによって、ビジネスのお金を生み出したり節約したりするビジネスルールもある。こうしたルールは手動の環境では使用されない。自動化されたシステムの一部としてのみ意味があるからだ。
たとえば、銀行員が新規ローンを作成するために使用するアプリケーションを想像してほしい。銀行は、ローン担当者が連絡先を収集・検証してから、候補者の与信スコアが 500 以上あることを確認するまで、ローンの支払い見積もりを提示しないと決めているとしよう。その場合、連絡先情報画面が全て入力され、値がきちんと検証され、与信スコアが基準値を超えていることが確認できるまでは、支払い見積もりの画面に進まないようにシステムを設定するだろう。
これは、ユースケースと呼ばれるものだ。ユースケースとは、自動化されたシステムを使用する方法を記述したものである。ユーザーから提供された入力、ユーザーに戻す出力、出力を生成する処理ステップなどを規定している。エンティティに含まれる最重要ビジネスルールとは違い、ユースケースはアプリケーション固有のビジネスルールを記述している。
ユースケースには、エンティティの最重要ビジネスルールをいつ・どのように呼び出すかを規定したルールが含まれている。ユースケースはエンティティのダンスを制御しているのである。
ユースケースは、ユーザーインターフェイスについては記述していない。インターフェイスからやってくるデータとそこから出ていくデータを略式で規定しているだけである。ユースケースを見ただけでは、そのアプリケーションがウェブなのか、シッククライアントなのか、コンソールなのか、純粋なサービスなのかを判断することは不可能である。
このことは非常に重要である。ユースケースはシステムのユーザーに対する見た目を記述するものではない。ユーザーとエンティティのインタラクションを支配するアプリケーション固有のルールを記述したものである。データがどのようにシステムに入出力されるかは、ユースケースとは無関係だ。
ユースケースはオブジェクトである。アプリケーション固有のビジネスルールを実装した関数を1つ以上持っている。また、入力データ、出力データ、それらがやり取りする適切なエンティティへの参照といった、データ要素を持っている。
エンティティは自身を制御するユースケースのことを知らない。これは、依存関係逆転の原則に従ったもうひとつの例だ。上位レベルのコンセプト(エンティティなど)は、下位レベルのコンセプト(ユースケースなど)のことを知らない。その代わり、下位レベルのユースケースは、上位レベルのエンティティのことを知っている。
では、なぜエンティティが上位レベルで、ユースケースが下位レベルなのだろうか?ユースケースはアプリケーション固有なので、システムの入力と出力に近い。エンティティは複数のアプリケーションで使用できるように一般化されているので、システムの入力と出力から遠く離れている。したがって、ユースケースはエンティティに依存し、エンティティはユースケースに依存していないのである。
リクエストとレスポンスのモデル
ユースケースは、入力データを期待し、出力データを生成する。ユースケースオブジェクトをうまく作りたければ、ユーザーや他のコンポーネントとのデータの通信方法について触れるべきではない。ユースケースクラスのコードが HTML や SQL のことを知る必要はない!
ユースケースクラスは、入力としてシンプルなリクエストデータ構造を受け取り、出力としてシンプルなレスポンスデータ構造を戻す。これらのデータ構造は何にも依存していない。HttpRequest や HttpResponse といった、標準的なフレームワークのインターフェイスから派生したものでもない。ウェブのことは何も知らないし、他のユーザーインターフェイスに関することも把握していない。
依存性がないことは非常に重要である。リクエストとレスポンスのモデルが独立していなければ、それらに依存するユースケースもリクエストとレスポオンスのモデルの依存性に間接的に結び付けられてしまう。
第 22 章:クリーンアーキテクチャ #
過去数十年にわたり、我々はシステムのアーキテクチャに関するさまざまなアイデアを見てきた。
- ヘキサゴナルアーキテクチャ
- DCI アーキテクチャ
- BCE
これらのアーキテクチャは、細部に多少の違いはあるものの、非常によく似ている。いずれも「関心事の分離」という同じ目的を持っている。そして、ソフトウェアをレイヤーに分割することで、この分離を実現している。また、それぞれ少なくとも、ビジネスルールのレイヤーと、ユーザーやシステムとのインターフェイスとなるレイヤーを持っている。
これらのアーキテクチャは、以下の特性を持つシステムを生み出す。
- フレームワーク非依存:アーキテクチャは、機能満載のソフトウェアのライブラリに依存していない。これにより、システムをフレームワークの制約で縛るのではなく、フレームワークをツールとして使用できる。
- テスト可能:ビジネスルールは、UI、データベース、ウェブサーバー、その他の外部要素がなくてもテストできる。
- UI 非依存:UI は、システムの他の部分を変更することなく、簡単に変更できる。たとえば、ビジネスルールを変更することなく、ウェブ UI をコンソール UI に置き換えることができる。
- データベース非依存:Oracle や SQL Server を Mongo、BigTable、CouchDB などに置き換えることができる。ビジネスルールはデータベースに束縛されていない。
- 外部エージェント非依存:ビジネスルールは、外界のインターフェイスについて何も知らない。
クリーンアーキテクチャはこれらのすべてのアーキテクチャを単一の実行可能なアイデアに統合したものである。
同心円は、ソフトウェアのさまざまな領域を表している。一般的には、縁の中央に近づくほどソフトウェアのレベルが上がっていく。円の外側は仕組み。内側は方針である。
このアーキテクチャを動作させる最も重要なルールは、依存性のルールである。
ソースコードの依存性は、内側(上位レベルの方針)だけに向かっていなければいけない。
円の内側は外側について何も知らない。特に、外側で宣言された名前は、内側にあるコードで触れてはいけない。これには、関数、クラス、変数、そのほかの名前付きソフトウェアエンティティが含まれる。
同様に、外側で宣言されたデータフォーマットは、内側から使ってはいけない。外側のフレームワークで生成されたフォーマットは特にそうだ。円の外側にあるものから内側にあるものに影響を及ぼしたくはない。
エンティティ
エンティティは、企業全体の最重要ビジネスルールをカプセル化したものだ。エンティティは、メソッドを持ったオブジェクトでも、データ構造と関数でも構わない。企業にあるさまざまなアプリケーションから使用できるなら、エンティティは何であっても問題はない。
企業が存在せず、単一のアプリケーションを作成しているだけなら、エンティティはアプリケーションのビジネスオブジェクトになるだろう。それは、最も一般的で、最上位レベルのルールをカプセル化したものである。外部で何か変化が起きても、それが変化する可能性は低い。たとえば、ページのナビゲーションやセキュリティを変更したとしても、これらのオブジェクトが影響を受けることはないだろう。特定のアプリケーションの操作に変更が発生しても、エンティティのレイヤーに影響を与えることはない。
ユースケース
ユースケースのレイヤーのソフトウェアには、アプリケーション固有のビジネスルールが含まれている。ここには、システムのすべてのユースケースがカプセル化・実装されている。ユースケースは、エンティティに入出力するデータの流れを調整し、ユースケースの目標を達成できるように、エンティティに最重要ビジネスルールを使用するように指示を出す。
このレイヤーの変更がエンティティに影響を与えることはない。また、このレイヤーが、データベース、UI、共通のフレームワークなどの外部の変更の影響を受けることもない。ユースケースのレイヤーは、そのような関心事からは分離されている。
ただし、アプリケーションの操作の変更がユースケースに影響を与え、それがユースケースのレイヤーのソフトウェアにまで影響することもある。ユースケースの詳細が変更された場合、このレイヤーのコードの一部も確実に影響を受ける。
インターフェイスアダプター
インターフェイスアダプターのレイヤーのソフトウェアは、ユースケースやエンティティに便利なフォーマットから、データベースやウェブなどの外部エージェントに便利なフォーマットにデータを変換するアダプターである。たとえば、GUI の MVC アーキテクチャを保持するのはこのレイヤーになる。プレゼンター、ビュー、コントローラーは、すべてこのインターフェイスアダプターのレイヤーに属している。モデルは、コントローラーからユースケースに渡され、ユースケースからプレゼンターとビューに戻されるデータ構造にすぎない。
同様に、このレイヤーでは、エンティティやユースケースに便利な形式から、永続フレームワーク(つまりデータベース)に便利な形式にデータを変換する。円の内側のコードは、データベースについて何も知らない。データベースが SQL データベースであれば、すべての SQL はこのレイヤー(特にデータベースに関係する部分)に限定する必要がある。
また、このレイヤーには、外部サービスなどの外部の形式から、ユースケースやエンティティが使用する内部の形式にデータを変換するアダプターも含まれる。
インターフェイスアダプター
最も外側の円は、フレームワークやツールで構成されている。たとえば、データベースやウェブフレームワークなどである。通常、このレイヤーにはコードをあまり書かない。書くとしても、円の次の内側とやり取りするグルーコードくらいである。
フレームワークとドライバのレイヤーには、詳細が詰まっている。ウェブも詳細。データベースも詳細。被害が抑えられるように、これらは外側に置いておく。
4 つの円だけ?
円は、概要を示したものである。したがって、この 4 つ以外にも必要なものはあるだろう。この 4 つ以外は認めないというルールはない。ただし、依存性のルールは常に適用される。ソースコードの依存性は常に内側に向けるべきだ。内側に近づけば、抽象度と方針のレベルは高まる。円の最も外側は、最下位レベルの具体的な詳細で構成される。内側に近づくと、ソフトウェアは抽象化され、上位レベルの方針をカプセル化するようになる。円の最も内側は、最も一般的で、最上位レベルのものになる。
境界線を越える
たとえば、ユースケースからプレゼンターを呼び出す必要があるとしよう。依存性のルールに違反するため、直接呼び出すことはできない。円の外側にある名前は、円の内側から触れることはできないからだ。したがって、ユースケースから円の内側にあるインターフェイスを呼び出すようにして、円の外側にあるプレゼンターがインターフェイスを実装することになる。
同じテクニックを使用して、アーキテクチャに含まれるすべての境界線を越えることができる。制御の流れがどのような方向であっても、依存性のルールに違反しないように動的なポリモーフィズムを活用して、制御の流れとは反対のソースコードの依存関係を生み出す。
境界線を越えるデータ
境界線を越えるデータは、単純なデータ構造で構成されている。好みに応じて、構造体やデータ転送オブジェクトを使うこともできる。単なる関数呼び出しの引数にすることもできる。ハッシュマップに詰め込んだり、オブジェクトにしたりすることもできる。境界線を越えて渡すのは、独立した単純なデータ構造であることが重要だ。エンティティオブジェクトやデータベースの行をそのまま渡すようなズルはしたくない。また、依存性のルールに違反するような依存性をデータ構造に持たせたくはない。
たとえば、多くのデータベースフレームワークは、クエリに対して便利なデータ形式を戻す。これを「行構造」と呼ぶこともある。行構造を円の内側の境界線を越えて渡したくはない。渡してしまうと、円の内側が外側について知ることになるため、依存性のルールに違反することになる。
したがって、境界線を越えてデータを渡すときは、常に内側の円にとって便利な形式にする。
まとめ
こうした単純なルールに従うのは、それほど難しいことではないだろう。ルールを守っていれば、いずれ多くの苦痛から解放してくれるだろう。ソフトウェアをレイヤーに分割して、依存性のルールを守れば、本質的にテスト可能なシステムを作り、それがもたらすメリットを受け取ることができる。システムの外部パーツ(データベースやウェブフレーム)が廃れたとしても、そうした要素を最小限の労力で置き換えることができる。
第 23 章:プレゼンターと Humble Object #
Humble Object パターンは、ユニットテストを実行する人が、テストしにくい振る舞いとテストしやすい振る舞いを分離するために生み出されたデザインパターンである。アイデアは非常にシンプルだ。振る舞いを 2 つのモジュールまたはクラスに分割するだけである。一つのモジュールは「Humble(控えめ)」で、ここにはテストが難しい振る舞いのみが含まれる。もう一つのモジュールには、Humble Object から取り除かれたテストしやすい振る舞いが含まれる。
たとえば、GUI のユニットテストは難しい。なぜなら、画面に適切な要素が表示されているかを確認するテストを書くのが非常に難しいからだ。しかし、GUI の振る舞いの大部分は、簡単にテストできる。Humble Object パターンを使えば、2 種類の振る舞いを Presenter と View の 2 つのクラスに分けられる。
プレゼンタービュー
View は、Humble Object である。こちらはテストが難しい。したがって、このオブジェクトのコードはできるだけシンプルに保っておく。GUI にデータを移動するが、そのデータを処理することはない。
Presenter は、テスト可能なオブジェクトである。アプリケーションからデータを受け取り、プレゼンテーション用にフォーマットして、View が画面に移動できるようにする。たとえば、アプリケーションがフィールドに日付を表示したいと思ったら、Presenter に Date オブジェクトを渡す。Presenter はそのデータを適切な文字列にフォーマットして、View から発見できる ViewModel というシンプルなデータ構造に配置する。
アプリケーションが画面にお金を表示したいと思ったら、Presenter に Currency オブジェクトを渡す。Presenter はそのオブジェクトに適切桁数と通過記号を付けてフォーマットして、文字列として ViewModel に配置する。値がマイナスのときに赤色にする必要があれば、ViewModel に適切な真偽値のフラグを付けておく。
画面にあるボタンにはすべて名前が付いている。名前は Presenter が配置した ViewModel に含まれる文字列である。ボタンをグレーアウトする必要があれば、Presenter が ViewModel に適切な真偽値のフラグを設定する。メニュー項目の名前は、Presenter が読み込んだ ViewModel に含まれる文字列である。ラジオボタン、チェックボックス、テキストフィールドの名前は、Presenter が読み込み、適切な文字列と真偽値として ViewModel に配置する。画面に表示する数値のテーブルは、Presenter が読み込み、適切にフォーマットした文字列として ViewModel に配置する。
画面に表示するもの、アプリケーションが制御するものはすべて、ViewModel に含まれる文字列・真偽値・列挙型として表現する。View がやるべきことは、ViewModel からデータを読み込み、画面に移動すること以外に残されていない。だからこそ、View は Humble なのである。
第 26 章:メインコンポーネント #
すべてのシステムには、そのほかのコンポーネントを作成・調整・監督するコンポーネントが少なくとも1つ存在する。私はこのコンポーネントを Main と呼んでいる。
Main コンポーネントは、究極的な詳細(最下位レベルの方針)である。システムの最初のエントリーポイントとなる。オペレーティングシステム以外に、このコンポーネントに依存しているものはない。Factory や Strategy などのグローバルな要素を作成し、システムの上位の抽象部分に制御を渡すことが、このコンポーネントの仕事になる。
依存関係については、この Main コンポーネントに DI フレームワークを使って注入する必要がある。Main に注入できたら、あとはフレームワークを使用せずに、Main が通常のやり方で依存関係をちりばめる。
Main は、汚れ仕事が最も似合うコンポーネントだ。
Main をアプリケーションのプラグインと考えよう。初期状態や構成を設定して、外部リソースを集め、アプリケーションの上位レベルの方針に制御を渡すプラグインである。プラグインなので、アプリケーションの設定ごとに複数の Main コンポーネントを持つこともできる。
たとえば、開発用、テスト用、本番用の Main を用意することもできる。あるいは、デプロイする国別、権限別、顧客別に用意することもできるだろう。
Main をアーキテクチャの境界の背後にあるプラグインとして考えると、設定の問題はもっと解決しやすくなるはずだ。
第 6 部:詳細 #
(訳注:「詳細」を意味する「detail」には、「些細」という意味もある。本書では「詳細」で統一しているが、両方の意味が含まれることに注意してほしい。)
- 第 30 章:データベースは詳細
- 第 31 章:ウェブは詳細
- 第 32 章:フレームワークは詳細
訳者あとがき #
本書で扱うテーマは「アーキテクチャ」。目次を見てすでにお気づきかもしれないが、みなさんが「アーキテクチャ」という言葉から想像するイメージとは、少し違った内容になっているだろう。著者の考えるアーキテクチャとは「設計」であり、一般的なイメージよりも具体的なものとなっている。その一方で、ビジネスドメインに関係ないことは「詳細」と割り切り、デリバリーの仕組みやフレームワークなどをすべて後回しにしようとする。おそらく異論のある方もいらっしゃるだろう。私もすっきりしていない。たとえば、ウェブアプリケーションを開発するときに、フレームワークを選定しないことがあるだろうか?
フレームワークに着手しないことが本当に正しいことなのかは、私にはまだよくわからない。本書で紹介されている例は、いずれも現代的なアプリの話ではない。正直、大昔の話を何度もされても困るのだが(翻訳も大変だし)、それでも「時代を超越した不変のルール」が存在するとして、著者はいつまでも原理・原則に忠実であろうとする。この真摯な態度については、心から見習いたい。彼が「ソフトウェアクラフトマンシップ(職人気質)」と呼んでいるものだ。