
機械学習の勉強のために次の本を読んだ。振り返りのために内容を補完しつつ整理しておく。
- 徹底攻略ディープラーニング G 検定ジェネラリスト問題集 第 2 版|インプレスブックス
- https://book.impress.co.jp/books/1120101164
第 1 章:人工知能をめぐる歴史と動向 #
- 「アーサー・サミュエル」による機械学習の定義「明示的にプログラムしなくても学習する能力をコンピュータに与える研究分野」
- 初期の素朴な自然言語処理プログラム(人工無能)「ELIZA(イライザ)」とその後開発された「PARRY(パリー)」は、会話を行い、その記録は「RFC439」として残されている。
- 「ニューロン」は単純な数値予測を行うことができる予測器で、ニューラルネットワークの最初単位。ニューロンでは、入力に対して、重みとバイアスに基づいて計算したあと、活性化関数もちいて出力を行う。
第 2 章:機械学習の基礎 #
- 「クラス(パターン)分類」と「クラスタリング」を混同しないように注意。
- クラス(パターン)分類:教師あり学習。あらかじめ設定したクラス(パターン)にデータを分類する。
- SVM(サポートベクターマシン)
- クラスタリング:教師なし学習。データからクラスタを抽出する。クラスタはデータから自動的に求める。
- k-means 法、ウォード法
- クラス(パターン)分類:教師あり学習。あらかじめ設定したクラス(パターン)にデータを分類する。
- 次元削減(次元圧縮):データの情報を失わないようにデータを低い次元に圧縮する手法の総称。例えば、身長と体重から BMI(肥満度)を計算する例は「(身長、体重) -> BMI」は2次元から1次元への次元削減である。
- 主成分分析(Principal Component Analysis, PCA):データの特徴量間の相関を分析することでデータ構造をつかむ手法。特に、特徴量の数が多い場合に、相関をもつ多数の特徴量から、相関のない少数の特徴量へと、次元削減することが主たる目的となる。ここで得られる少数の特徴量を「主成分」という。
- 基礎集計:前処理よりもさらに前に行われる作業のこと。(平均、分散などを計算してみる、相関行列を計算してみる、など)
- 機械学習のデータの前処理
- 正規化(normalization):データを一定の規則に基づいて変形し利用しやすくすること。主にデータの大きさを最小 0 ~ 最大 1 にスケーリングすることを指す場合が多い。
- 標準化(standardization):データの平均を 0、分散を 1 にすること。
- 特徴量エンジニアリング:モデルが認識しやすい特徴をデータから作ること。例えば「カテゴリカル変数(性別、髪の色、国籍などの何らかの種類を表す変数)」をカテゴリカル変数であるとわかる形に変換(encoding)することは特徴量エンジニアリングの1つ。具体的にはたった 1 つの成分だけが 1、残りの成分は 0 という形の特徴量に変換する。この形のことを「one-hot-encoding」という。
- 「基礎集計 -> 前処理 -> 特徴量エンジニアリング」の順に実施される。
第 3 章:機械学習の具体的手法 #
- 回帰分析:説明変数は「手がかりとなる変数」、目的変数は「予測したい変数」。例えば、その日の気温から飲料の売り上げを予測する場合は、気温が説明変数で、売り上げが目的変数。
- 単回帰分析:1つの説明変数から目的変数を予測する(気温から飲料の売り上げを予測)
- 重回帰分析:複数の説明変数から目的変数を予測する(駅からの距離、築年数、部屋の広さ、から家賃を予測)
- 相関係数:相関係数は常に -1 から 1 の間の数値を取る。1 で比例関係、-1 で反比例関係、0 は相関がないことを意味する。
- 多重共線性:英語では multicollinearity であり、マルチコと呼ばれている。多重共線性とは、相関係数が高い(1 または -1 に近い)特徴量の組を同時に説明変数に選ぶと予測がうまくいかなくなる現象のことをいう。そのため、特徴量エンジニアリングにおいては、マルチコが発生するペアを作らないように、各ペアの相関係数を観察して特徴量を取り除く必要がある。
- パーセプトロンは、複数の入力データ(入力信号)に対して、一つの値を出力する関数のこと。単純パーセプトロンを使って解ける問題は、直線を使って分離できるものに限られる。このような問題を「線形分離可能」という。線形分離不可能な問題は、パーセプトロンを組み合わせて多層パーセプトロンにすることで解決できる。
- SVM(サポートベクターマシン)はマージンの最大化というコンセプトに基づくが、「スラック変数」を調整することで誤分類を許容することができる。このようなエンジニアが事前に調整する変数をハイパーパラメータという。
- エンジニアが事前に調整するものを「ハイパーパラメータ」と呼び、学習によって最適化する変数を「パラメータ」と呼ぶ、混同しないこと。
- kNN 法(k-nearest neighbors、k 近傍法):対象のオブジェクトデータのクラス分類は、そのデータから近い順に k 個のデータを見て、それらの多数決によって所属クラスを決定するというもの。シンプルに実装できるアルゴリズムであるが、各クラスのデータ数に偏りがあると、判定結果が不正確になりやすい。
第 4 章:基礎数学 #
- スカラ(Scalar)、ベクトル(Vector)、行列(Matrix)、テンソル(Tensor)
- 「スカラー」「ベクトル」「行列」の積
- 「スカラー・ベクトル・行列・テンソル」の意味
- 統計学は、得られているデータから法則性や知見を数学的に得る分野である。機械学習もある意味、統計学に含まれているということができる。統計学は次の2つに大別できる。
- 記述統計:手元のデータの分析を行う。手元のデータについて、代表値を求めたり、傾向を分析するなど。
- 推計統計:手元のデータの背後にある母集団の性質を予測する。推計統計の応用例として、選挙の得票推定、視聴率推定などがあげられる。
第 5 章:ディープラーニングの概要 #
ニューロンの模式図
ニューロンは、ニューラルネットワークの最小単位である。
x:入力、w:重み、b:バイアス、f:活性化関数、y:出力
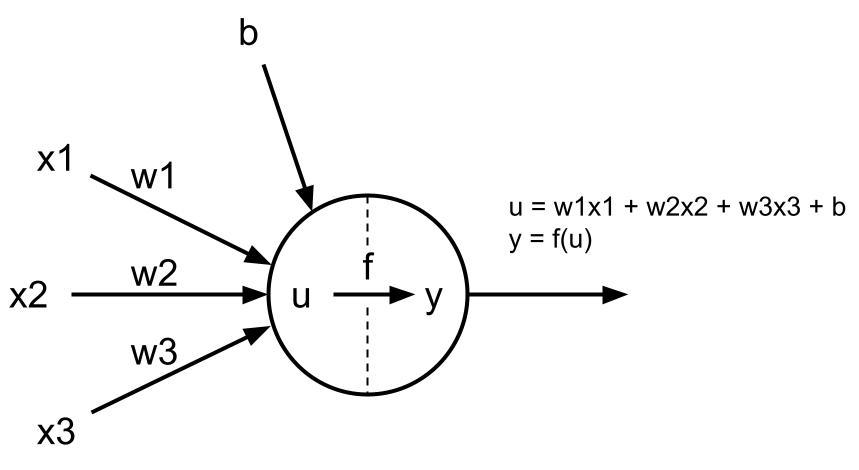
x1=1, x2=-1, x3=1
w1=0.8, w2=-0.6, w3=0.2
b=-1
f=max(0, x) ... ReLU 関数
このとき、
u=(1*0.8) + (-1*-0.6) + (1*0.2) -1
y=max(0, u)
となり、
y=0.6
- 代表的な活性化関数の例
- ステップ関数
- シグモイド関数
- ReLU(Rectified Linear Unit, レル)関数
- ソフトマックス関数
- 教師データを用いたディープニューラルネットワークの学習は次の流れで行われる
- 教師データを用いて予測を行う。ニューラルネットワークを左から右へと順番に計算する(順伝播)。その予測値と正解ラベルを比較して誤差を計算する。これをいくつかの教師データについて繰り返し、その都度誤差を足し合わせる。
- 累積された誤差の値が小さくなるよう、勾配降下法を用いて各枝の重みを更新する。枝の重みはニューラルネットワークの右から左へと更新される(逆伝播、誤差逆伝播法/バックプロパゲーション)。
- 誤差が最小化されるよう 1 と 2 を繰り返す。
- 勾配降下法:最も求めたいのは大域的最適解だが、勾配降下法で求めた値が大域的最適解なのか局所最適解なのかの判断はできない。そのためディープニューラルネットワークの学習においては、局所最適解が求められれば誤差はそれなりに小さくなるものと考え、妥協するスタンスをとっている。
- 大域的最適解:誤差の値を最も小さくする値
- 局所最適解:その周辺では誤差の差が小さいが、最小値を実現する(=大域的最適解)ではない解
- 停留点:大域的最適解でも局所最適解でもないが、勾配が 0 になる点
- 鞍点(あんてん):ある方向から見ると極小値だが、別の方向から見ると極大値になる点
- ディープニューラルネットワークにおける重みの更新タイミング:「エポック:訓練データを何度学習に用いたか」、「イテレーション:重みを何度更新したか」
- 逐次学習:訓練データ1つに対して、重みを1回更新する。このように実施する勾配降下法を「確率的勾配降下法」という。
- ミニバッチ学習:訓練データを分割したまとまりに対して、重みを1回更新する。このように実施する勾配降下法を「ミニバッチ勾配降下法」という。
- バッチ学習:訓練データすべての誤差を計算した後、重みを1回更新する。つまり、イテレーションとエポックが等しくなる。このように実施する勾配降下法を「(単に)勾配降下法」あるいは「バッチ勾配降下法」という。
第 6 章:ディープラーニングの手法 #
- 過学習とは、訓練誤差が小さいにも関わらず、汎化誤差が小さくならない状態をいう。
- オートエンコーダ(自己符号化器)はエンコーダとデコーダからなるニューラルネットワークであり、入力層と出力層のノード数が同じで、中間層のノードがそれよりも少ないもののことをいう。正解ラベルとして自分自身を用いることにより、次元削減が得られる。
- 隠れ層では入力層より次元(ノード)が減っているにも関わらず出力層ではもとの入力層の内容を復元できているということはつまり、隠れ層では特徴的な情報だけに圧縮できていることを意味する。入力層から隠れ層への処理をエンコードといい、隠れ層から出力層への処理をデコードという。
- RNN(再帰型ニューラルネットワーク)とは、内部的に閉路(あるいは再帰構造とも)を持つニューラルネットワークの総称である。RNN は過去の情報を保持することができるため、時系列データの解析(音声、動画、自然言語など)によく用いられる。従来の RNN では難しい、遠い過去の入力を現在の出力に反映させることを可能にした LSTM(Long Short-Term Memory)の改良などがある。
第 7 章:ディープラーニングの研究分野と応用 #
- 形態素解析:テキストデータから文法・単語に基づき、言語で意味を持つ最小単位である形態素に分割し、その形態素の品詞を判定すること。
- 自然言語処理のフローは一般的に次の通り。
- 形態素解析を用いて、文章を形態素に切り分ける。
- データをクレンジングし、不要な単語などを取り除く。
- BoW(Bag-of-Words)などを用いて、形態素解析を行なったデータをベクトル形式に変換する。
- TF-IDF(Term Frequency-Inverse Document Frequency)などを用いて各単語の重要度を評価する。
- Word2Vec:単語をベクトルとして表現し、意味の近さや計算を行えるようにする仕組み。2013 年に Google が開発。
- 王様(0.4, 0.1, 0.9, 0.4)
- 女王(0.5, 0.2, 0.3, 0.4)
- 男(0.1, 0.0, 0.8, 0.2)
- 女(0.2, 0.1, 0.2, 0.3)
- こうすることで、王様と女王の単語の距離の近さを表現したり、王様から男を除いて女を加えると女王に近くなるなどの計算が行える。
- マルチモーダル情報処理:ロボットにおいて、視覚(カメラ)・聴覚(マイク)・触覚(圧力センサ)などの異なったセンサ情報をディープニューラルネットワークで組み合わせて統合的に処理する仕組み。
- トピックモデル:k-means 法やウォード法と同様にクラスタリングを行うモデルだが、データをひとつのクラスタに分類する k-means 法などとは異なり、トピックモデルでは複数のクラスタにデータを分類する。名前の由来は、文章を潜在的なトピック(単語の出現頻度分布)から確率的に現れるものと仮定し、文章の分析を行う手法。各トピックの確率分布を推定することができれば、文章の傾向の分析や現れやすい単語の特定、次に予測される文章の形の予測などを行うことが期待できる。
- 敵対的攻撃(Adversarial attack):データにノイズを混入させ、それにより人工知能の判断を誤らせる攻撃のこと。対策には、学習データに敵対的事例を入れておく「敵対的学習」や、入力が敵対的事例かを判別するニューラルネットワークを作る「ADN(Adversary Detector Network)」のほか、活性化関数に「k-WTA(k-Winners-Take-All)」の用いることも対策になるということが発見されている。
- 音声認識:人間が話す音声から、その内容のテキストを生成すること。音声合成の逆。
- 音声合成:テキストの内容から、人間が話す音声をを生成すること。音声認識の逆。
第 8 章:人工知能と法律・契約および動向 #
- 著作権保護の対象となる著作物とは「思想又は感情を創作的に表現したものであつて、文芸、学術、美術又は音楽の範囲に属するもの」をいう。
- AI が楽曲のすべてを自動生成した場合はその創作物に対して著作権は発生しない。AI が部分的に作成したものを人間がつなぎ合わせて作った場合はそれをつなぎ合わせた人間に対して著作権が発生する。
- 特許法において、発明は「自然法則を利用した技術的思想の創作のうち高度のもの」をいい、「新規制、進歩性」があり「産業上利用できる」場合は特許権が認められる。
- 現行法制度上、自然人ではない AI が発明したものについては特許権は認められない。
- AI ソフトウェア開発の工程
- アセスメント:導入可能性の評価
- PoC:仮説検証
- 開発
- 追加学習
- 不正競争防止法における「営業秘密」とは「秘密として管理されている生産方法、販売方法その他の事業活動に有用な技術上又は営業上の情報であって、公然と知られていないもの」と定義されている。すなわち以下の3要件を満たすものが営業秘密と解釈される。
- 秘密管理性:その情報が秘密として管理されていること
- 有用性:有用な情報であること
- 非公知性:一般に知られている情報でないこと
- 不正競争防止法における「限定提供データ」とは「業として特定の者に提供する情報として電磁的方法により相当量蓄積され、及び管理されている技術上又は営業上の情報」と定義されている。すなわち以下の3要件を満たすものが営業秘密と解釈される。
- 限定提供性:特定の者に提供する情報であること
- 相当蓄積性:電磁的方法により相当量蓄積されていること
- 電磁的管理性:ID、パスワードなどの電磁的方法により管理されていること
- 透明性レポート:ユーザの個人情報をどのように収集、利用、保護するかについて、企業の基本的な指針・方針を示すレポートのこと
- LAWS(自律型致死性兵器:Lethal Autonomous Weapons Systems):自動的に攻撃目標を設定することができ、致死性を有する完全自律型兵器のこと。
第 9 章:総仕上げ問題 #
- 第3次 AI ブームのきっかけとなった ILSVRC は、ImageNet というデータセットを使った一般物体認識のタスクにおける性能を競うコンペティションである。ILSVRC2012 では、ジェフリー・ヒントン率いるチームのディープラーニングを使ったモデルが、前年までの優勝モデルである SVG(サポートベクターマシン)を遥かに凌駕する性能を叩き出した。
- IBM のディープ・ブルーは 1996 年にチェスの世界チャンピオンを破った。しかしこのときはブルートフォース式に総当たりで指手を探索する手法だった。
- 「データサイエンス」とは、データに関する研究全般を指し意味が非常に広い。機械学習はデータサイエンスの一手法として用いられる。
- フレーム問題はまだ解決されていないが、フレーム問題を乗り越えた AI を「強い AI(あるいは汎用 AI)」、乗り越えていない AI を「弱い AI(あるいは特化型 AI)」と呼ぶことがある。
- SVM(サポートベクターマシン)は当初、2クラス分類のアルゴリズムとして考案されたが、多クラス分類をはじめさまざまなことに応用されている。例えば「カーネル法」は決定境界を非線形にするための工夫であり、「カーネルトリック」は計算量を大幅に削減する工夫である。
- 決定木:「条件分岐の繰り返し」と「情報利得の最大化(=不純度の減少量の最大化)」を繰り返すことにより分類あるいは回帰するための単純なアルゴリズム。単純であることから、データの前処理が少なく済んだり、データのスケールを事前に揃えておく必要がないことや、分析結果の説明が容易であるという利点がある。
- 主成分分析の結果の「寄与率」を調べることで各成分の重要度がわかり、「主成分」を調べることで各成分の意味を推測することができる。
- アンサンブル学習とは、複数のモデルを作り、一般的に、分類問題には多数決を、回帰問題には平均を結果として採用する手法。
- ランダムフォレストは、大雑把にいうとバギングと決定木を組み合わせたもので、実務でも頻繁に用いられる優れたアルゴリズム。決定木の良さを引き継ぎつつも、過学習を起こしやすいという弱点を解消している。
- スパース:ほとんどが 0 で、稀に 0 以外が並ぶデータのことをスパース(なデータ)と呼ぶ。スパースは日本語で「疎」の意味。
- 次元の呪い:機械学習においてデータの次元が増えるごとにさまざまな不都合が生じやすくなるという法則性のこと。
- ハイパーパラメータのグリッドサーチ:事前に設定したハイパーパラメータの各候補に対して交差検証で精度を測り、最も精度が高かったハイパーパラメータの組みを最良のハイパーパラメータとして採用する手法。多数のモデルを作る必要があり計算量が多くなるが、実践ではよく使用されている手法である。
- ディープラーニングは複雑な関数の近似が可能であるという強みの一方で、過学習や勾配消失問題を起こしやすいことや、事前に調整すべきパラーメータ数が非常に多いという難点もある。
- ディープニューラルネットワークにおいて、勾配降下法を用いて重みを更新するとき、重みの更新幅はエンジニアが調整すべきハイパーパラメータであり、これを「学習率」という。
- ディープラーニングのフレームワーク
- Tensorflow(テンソルフロー):Google が開発。
- Keras(ケラス):ディープラーニングに特化した Tensorflow のラッパー。
- Chainer(チェイナー):構築と同時に評価を行う Defined-by-Run 形式を採用。Preferred Networkds が開発。
- PyTorch(パイトーチ):Chainer から派生。
- アシロマ AI 原則:AI による軍拡競争は避けるべきだとする宣言。アシロマは米国カリフォルニア州の地名。
- GAN は画像の生成だけでなく、文章の生成などにも用いられる。
- XAI(Explainable AI, 説明可能な AI):一般的に、モデルの説明可能性とそのモデルの性能はトレードオフの関係にある。