
Cloud Run では最小インスタンス数の設定が可能で、これを1以上に設定することでコールドスタート問題への対策が可能となります。
ただし、これは常にコンテナを起動していることになるので当然その分の料金がかかります。CPU 1 個、メモリ 512MB の最小限のリソース構成でも1台あたり約 10 USD/月の費用となります。
ここで、最小インスタンス数を設定する代わりに、定期的に Cloud Run にアクセスするように仕組みを作ることで、実質的に常にコンテナを起動しているのと同じような効果を得ることができます。これは最小インスタンス数を設定する方法と比べて費用を非常に安く抑え、ほぼ0円にすることができます。
以降でこの方法について説明していきます。
Cloud Run のライフサイクル #
費用が安くなる仕組みを理解するために Cloud Run のライフサイクルを知ることが重要です。
- Cloud Run 上のコンテナのライフサイクル | Google Cloud 公式ブログ
- https://cloud.google.com/blog/ja/products/serverless/lifecycle-container-cloud-run
上記の記事中で紹介されていますが、Cloud Run のライフサイクルは以下のようになっています。
スタート -> リクエストに応答 -> アイドル状態 -> シャットダウン -> ストップ
Cloud Run にリクエストが届くと、コンテナが開始されます(「スタート」)。コールドスタートによるレイテンシとは、この起動処理に時間がかかるため発生する遅延を指しています。
その後リクエストに応答するとコンテナは役目を終えますが、すぐにはシャットダウンされずアイドル状態へと移行します。アイドル状態のときに新たなリクエストを受け付けると、コンテナはそのリクエストに応答します。このとき「スタート」の行程を経ないため、コールドスタートは発生しません。
そして Cloud Run の仕様として、アイドル状態のときには費用は発生しません。
アイドル状態のコンテナには費用が発生しません。費用が発生するのは、コンテナの起動時、リクエストの処理時(100 ミリ秒の粒度)、シャットダウン時に使用するリソースに対してのみです。
https://cloud.google.com/blog/ja/products/serverless/lifecycle-container-cloud-run
Cloud Run は、すべてのリクエストを処理した後、すぐにはインスタンスをシャットダウンしません。コールド スタートの影響を最小限に抑えるために、Cloud Run は一部のインスタンスを最大で 15 分間アイドル状態にすることがあります。このようなインスタンスは、トラフィックが急増した場合にすぐリクエストを処理できます。
https://cloud.google.com/run/docs/about-instance-autoscaling
つまりアイドル状態は、費用がかからずコールドスタートも発生しない、開発者にとっては理想的な状態と考えることもできます。
なお、アイドル状態の維持時間は最大 15 分とだけ明記されており、最小時間は定められていないことには注意してください。
ヘルスチェックによって意図的にアイドル状態を維持する #
コンテナに定期的にリクエストを送信すれば、コンテナは リクエストに応答 -> アイドル状態 -> リクエストに応答 -> アイドル状態 -> ... を繰り返すことになります。
ここで、定期的にリクエストを送信するという行為について、観点を少し変えて考えてみると、これはヘルスチェックを意図して行われることもあります。定期的にサーバにリクエストを送信して、正常なレスポンスが返ってくることを確認することで死活監視をするといった具合です。
そこで、定期的なヘルスチェックを実施しつつ、同時にその結果としてコンテナをアイドル状態に保つように仕組みを作ってみます。
1.ヘルスチェック用のエンドポイントを用意する #
Cloud Run で運用するアプリケーションに /health のようなヘルスチェック用のエンドポイントを用意します。HTTP ステータス 200 OK を返すだけのシンプルなもので構いません。
ヘルスチェック用のエンドポイントとして /healthz が慣例的に使われることも多いですが、Cloud Run では末尾が z のパスは予約済みの URL となっており利用できないことに注意してください。
予約済みの URL パス
次の URL パスは使用できません。
/eventlog/_ah/で始まるパス。- 末尾が
zのパス。
2.Cloud Monitoring を作成する #
あとは死活監視ツールで先ほどのエンドポイントに定期的にリクエストを送るようにすれば完了です。幸いにも GCP のサービスの1つである Cloud Monitoring がこの機能を提供しています。
Monitoring の Uptime checks から新規の死活監視スケジュールを登録します。以下は入力例です。
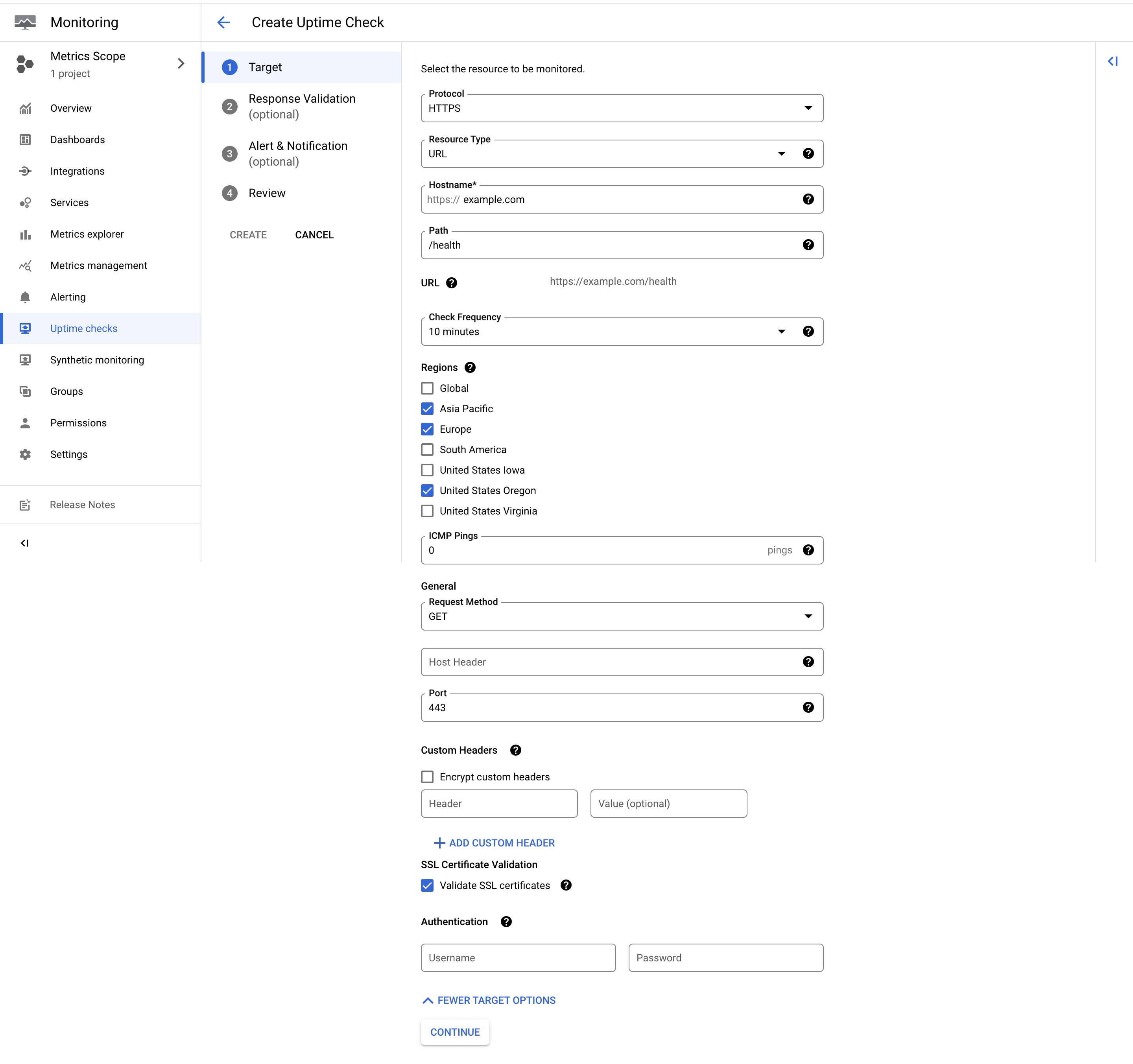
重要な項目は Check Frequency と Regions です。
Check Frequency
Choose 1, 5, 10, or 15 minutes. For example, if you select 5 minutes, each geographic location attempts to reach your service once in every 5 minute period. Using the default 6 locations, and checking every 5 minutes, your service would see an average of 1.2 requests per minute. Checking every 1 minute, your service would see an average of 6 requests per minute.
Regions
Select the geographic regions where your check is to receive requests. You must have at least 3 active locations. Selecting Global always sends requests from all available locations.
リクエストの頻度は平均して (Check Frequency / Regions の数) 分に1回 になります。例えば、Check Frequency を 15 分、Regions を3つ選択した場合は、平均して5分に1回のリスエストが発生します。
Regions の数を増やすだけ Cloud Monitoring の費用が大きくなる(それでも無料枠に収まるはずですが)ため、必要性がなければ Regions は最小値である3箇所を選択します。ここでは Regions を3にした前提で進めます。
Check Frequency と平均リクエスト発生頻度は次のとおりです。
- Check Frequency を 1 にすると平均して 20 秒に1回のリクエスト
- Check Frequency を 5 にすると平均して1分 40 秒に1回のリクエスト
- Check Frequency を 10 にすると平均して3分 20 秒に1回のリクエスト
- Check Frequency を 15 にすると平均して5分に1回のリクエスト
ただし「平均して N 分に1回のリクエスト」が「N 分ごとに1回リクエスト」と同義ではないことに注意してください。
例えば各 Regions がすべて同一タイミングでリクエストを送る場合、「Check Frequency の数字分ごとに1回のリクエスト」という挙動になります。逆に各 Regions がそれぞれ等間隔に間を空けてリクエストを開始する場合には「N 分ごとに1回リクエスト」となります。
各 Regions がそれぞれどのタイミングでリクエストを送るのかは Cloud Monitoring では明記されていないためはっきりとは分かりませんが、実行結果を見る限りだとバラバラのタイミングでリクエストを開始しているようです。
Cloud Run のコンテナをアイドル状態で維持するためには、シャットダウンのプロセスに移行する前に次のリクエストを送信する必要があります。
ここは実際に運用しながら調整していくしかありませんが、私は「Regions: 3、Check Frequency: 15」の設定で、常にアイドル状態を維持(=コールドスタートに遭遇しない)して運用できているように思います。
少し運用してみて、コールドスタートが発生しているようであれば Check Frequency をさらに小さい数字に調整すると良いでしょう。
また Cloud Monitoring ではリクエストに対して期待するレスポンス(例えば 200 OK)が返ってこなかった時には Slack などに通知するように設定することができます。Cloud Run に何らかの不具合が起きている場合は、このようにして検知することで死活監視を行います。
参考 #
- Google Cloud Run を常にウォーム状態にする方法 | エンジニアの眠れない夜
- Google Cloud の稼働時間チェックを使ったお手軽死活監視の紹介 - NTT Communications Engineers’ Blog