
あなたのシステムはきちんと動いていると言えますか? 本書は、システムのどの部分をどのように監視すべきか、また監視をどのように改善していくべきかについて解説する書籍です。
前半で監視のベストプラクティス、デザインパターン/アンチパターンを示して、監視の基本原則を詳しく説明し、後半でフロントエンド、アプリケーション、サーバ、ネットワーク、セキュリティの各テーマで強力な監視の基盤を設計して実装するための方法を示します。
書籍名のとおり、監視(システムのモニタリング)作業の入門者に向けて情報が整理されている。前半では、監視に関する考え方やチームでの運用方法といったところを説明し、後半では、フロントエンド、アプリケーション、サーバ、ネットワーク、セキュリティといったシステムの各構成要素ごとに何をどのように監視するのが良いかを一通り解説している。
本書は約 200 ページほどの薄い本であり、それぞれの項目の説明は入門レベルの必要最小限に抑えられている。この本で概要を把握した後、例えばネットワークの監視などといった特定分野について詳細に知りたい場合は、それに特化したより専門的な本を手に取るのが良さそうだ。
読書記録を兼ねて、本書を内容の一部を以下にメモしておく。
監視の原則 #
役割としての監視ではなく、スキルとしての監視 #
会社が成長するにつれて、チームメンバーは特定の役割を受け持つのが普通になってきます。私は各人が専門化した役割を持っている巨大企業で働いたことがありますが、そこではログ収集の専門化、Solaris サーバ管理の専門化、さらには他の人のために監視の仕組みを作って管理する人すらいました。
一見するとこの仕組みは効率が良さそうです。専門化したロールを作ることでメンバーが役割に集中できるのですから。しかし、監視となると問題があります。理解もできないものを監視する仕組みなんて作れるでしょうか?それは難しいでしょう。つまり、このやり方はアンチパターンです。
監視とは役割ではなくスキルであり、チーム内の全員がある程度のレベルに至っておくべきです。構成管理ツール、あるいはデータベースサーバの管理方法に詳しいのは1人だけと言う状況にはしないのに、監視となると1人でもよいと思ってしまうのはなぜでしょうか。監視は他の仕組みから孤立した仕組みではなく、皆が責任を持つことを主張してください。
アラートに関しては OS のメトリクスはあまり意味がない #
システム管理者としてキャリアを始めた頃、私はリードエンジニアのところへ行きあるサーバの CPU 使用率が高いことを伝え、どうしたらよいか聞きました。彼の答えは私を驚かせるものでした。「そのサーバはやるべき処理はしているんだろう?それなら、何も問題はないじゃないか。」
動かすサービスによっては、元々リソースをたくさん使うものもありますが、それで問題ないのです。MySQL が継続的に CPU 全部を使っていたとしても、レスポンスタイムが許容範囲に収まっていれば何も問題はありません。これこそが、CPU やメモリ使用率のような低レベルなメトリクスではなく、「動いているか」を基準にアラートを送ることが有益である理由です。
最優先はユーザ視点での監視 #
あなたのアプリケーションとインフラは複雑で、たくさんの可動部分から構成されており、どこが壊れてもおかしくありません。計測する必要がありそうな箇所はたくさんありますが、手をつけるのに最適な場所があります。それはユーザです。
まず監視を追加すべきなのは、ユーザがあなたのアプリケーションとやり取りをするところです。Apache のノードが何台動いているか、ジョブに対していくつのワーカが使用可能かといったアプリケーションの実装の詳細をユーザは気にしません。ユーザが気にするのは、アプリケーションが動いているかどうかです。とにかくユーザ視点を優先した可視化が必要です。
最も効果的な監視ができる方法の1つが、シンプルに HTTP レスポンスコード(特に HTTP 5xx 番台)を使うことです。その次として、リクエスト時間(レイテンシとも言う)も有益です。このどちらも何が問題なのかは教えてくれませんが、何かが問題で、それがユーザに影響を与えていることはわかります。
ユーザ視点優先の監視によって、個別のノードを気にすることから解放されます。データベースサーバの CPU 使用率が急上昇しても、ユーザが影響をうけていないなら、それは本当に問題でしょうか。
とはいえ、私はこれがアプリケーションを計測すべき唯一の場所であるとは言っていません。ユーザから始めるべきではありますが、Web ノードやワーカノードといったコンポーネントの監視にすばやく対象を広げていく必要があります。必要なだけ深く広く対象を増やしつつも、「このメトリクスはユーザへの影響をどう教えてくれるだろうか」と常に自問自答してください。
継続的に改善する #
Google、Facebook、Twitter、Netflix、Etsy といった進歩的な企業のことを調べて、彼らが監視についていかに素晴らしいことをやってきたかに驚いた人もいるでしょう。そういった企業がいかにして高度な監視の仕組みを作ったかについて書いたブログもたくさんあります。しかし、それらの企業が今日の状態に至るまでに何年もかかっていることを忘れている人もいるようです。それぞれの企業内では、仕様が変わり組織が成熟するにつれて、使われなくなったツールがあり、新しく作られたツールがあります。
あなたはおそらく、このように大きく成熟した企業で世界レベルの監視サービスを作る責任者というわけではないでしょう。しかし、監視の仕組みを改善する取り組みは時間と共に変わっていき、明日は世界レベルになるであろう仕組みも、1年後にはそうではない可能性もあります。いくらうまく運用していても、要求される仕様が変わったり業界が進歩するにしたがって、2年あるいは3年で監視の仕組みを再構築しなおすことになるかもしれません。
つまり、世界レベルの仕組みは1週間でできるものではなく、数ヶ月あるいは数年間にわたる継続した注意深さと改善から生まれるものです。あなたはこの長い道のりの途中にいるのです。
避けられないオンコールを少しでも緩和する #
ああ、古き良きオンコール。この本の読者の多くは、公式非公式を問わず、キャリアのどこかのタイミングでオンコール担当になったことがあるでしょう。担当になったことがない人に向けて説明すると、オンコールとは、何か問題が起きたという呼び出しに応えられるようにしている担当のことです。呼び出しを受けるのがいつもあなたなら、あなたはいつもオンコールだということです。(これはよくないことです。)
オンコールの経験がある人は、オンコールが最悪の時間になることも知っているでしょう。誤報、分かりにくいアラート、場当たり的な対応に悩まされます。数ヶ月後には、怒りっぽくなる、睡眠不足、心配性などといった、燃え尽きの症状が出始めます。
しかしそんな風になる必要はありません。どうしたらそうならないかを教えましょう。夜中にコンピュータがおかしな動作をしないようにはできませんが、そのせいで必要ないのに叩き起こされることがないようにはできます。
- 誤報を修正する
- 誤報はありふれた日常的なことです。100% 正確なアラートを実現するのは、非常に難しく、まだ解決されていない問題です。たとえ 100% の正確性は絶対に実現できないとしても、それに向けて努力はすべきです。
- 無用の場当たり的対応を減らす
- 監視自体は何も修復してはくれません。何かが壊れたら、あなたがそれを直す必要があります。場当たり的対応をやめるには、その基礎にあるシステムを改善するのに時間を使わなくてはなりません。
- 上手にオンコールローテーションを組む
- 常にオンコール担当でいるのは人を燃え尽きさせる最高の方法です。だからこそ、オンコールローテーションするのは素晴らしい考え方であると言えます。4人のチームがあるとしましょう。各人が1週間ずつ、水曜午前 10 時に始まり1週間後に終わるという4周単位のローテーションを組みます。これで、全員が1週間ずつ決まった順番でオンコールを担当し、3週間は担当を外れ、そしてまた繰り返すというローテーションになります。カレンダーの週に合わせるのではなく、出勤日にオンコールのローテーションを始める点が重要です。これによって、チーム内でオンコールの引き継ぎができるようになります。オンコールを終える人が、オンコールを始める人と、注意を要する進行中の出来事やその週に気づいたパターンなどについて議論できるのです。
オンコールに対する補償
オンコール担当に対する補償に近い以下の2つについても考えます。
- オンコールシフトの直後に、有給休暇を1日取らせます。オンコール担当は神経を使う仕事であり、回復のための日は確保する価値があります。
- オンコールシフトごとに手当を払います。オンコールシフトのたびに手当を支払うのは、医療業界では普通のことです。金額は、看護師に対する1時間2ドルから、神経外科医に対する1日 2,000 ドルまでさまざまです。
オンコールは、睡眠の質や家族との時間など、生活の多くの部分に対してよくない影響があります。この業界の悪しき部分に対して補償金を出すのは、公平なことだと言えるでしょう。
インシデント管理での役割 #
インシデント管理とは、発生した問題を扱う正式な手順のことです。テクノロジ業界向けにいくつかのフレームワークが存在しており、そのうち最も広く使われている1つが ITIL から来たものです。ほとんどの単純なインシデントでは、ITIL のプロセスはうまく動きます。
数分以上かかる本当のサービス停止を伴うインシデントについてはどうでしょうか。その場合、明確に定義された役割が重要になります。それぞれの役割は1つの機能が割り当てられ、2つ以上の兼務は避けるべきです。
- 現場指揮官(IC, incident commander):この人の仕事は、決断することです。特に、この役割の人は改善、顧客や社内とのコミュニケーション、調査にはかかわりません。サービス停止に関する調査を監督する役割であり、それだけです。
- スクライブ(scribe):スクライブ、すなわち初期の仕事は、起こったことを記録しておくことです。誰が何をいつ行ったのか。どんな決断がされたのか。どんなフォローアップをすべき事項が見つかったのか。この役割の人も、調査や改善は行いません。
- コミュニケーション調整役(communication liaison):この役割の人は、社内外問わず利害関係者に最新情報のコミュニケーションをとります。ある意味で、インシデント対応する人や何が起きているのか知りたい人たちにとって、この人が唯一のコミュニケーションポイントです。利害関係者(経営者など)が、インシデントの解決に取り組んでいる人たちに最新情報を直接聞いてしまってインシデント解決を邪魔することがないようにするのも、仕事の1つです。
- SME(subject matter expert):実際にインシデント対応する人です。
インシデント管理の役割についてよく見るアンチパターンの1つに、チームや会社での通常の上下関係に、インシデント対応の際も従ってしまうということがあります。例えば、チームのマネージャが常に IC になってしまうといったことです。インシデント管理の各役割は、通常時のチームでの役割と一緒である必要はありません。むしろ私としては、チームのマネージャは IC よりもコミュニケーション調整役にし、エンジニアを IC にすることをおすすめします。このやり方だと、マネージャは割り込みからチームを守り、リスクとトレードオフを評価するのに最適な人、つまりエンジニアが決断する役割になるので、うまくいく可能性が高くなります。
監視戦略 #
設計のときから監視の仕組みを考える #
もしかしたら「自分のアプリケーションにそんな監視できるようなデータはない。どうやって存在しないものを監視すればいいんだ」と思っているかもしれません。
これまで取り上げたように、監視とは何かが起こった後に追加すればいいものではありません。アプリケーションやインフラのパフォーマンスに対する可視性を上げるには、デザインがなくてはなりません。
自動車メーカーが、燃料タンクにガソリンがどのくらい入っているか計測する方法がない車を作ったとしたらどうでしょうか。あるいは速度を測れないとしたらどうでしょうか。これらは、車が完成してから単に取り付ければよいというものではありません。ごく最初の段階から車にデザインされているものです。
ありがたいことに、私たちは車を作っているわけではないので、出荷済みの車全部に燃料計をつけるような作業と比べると、ずっと早いフィードバックループを使って機能を変更できます。満足するまで監視を追加し、改善を続けるために、アプリケーションやインフラを変更する能力があります。必要な計測データをアプリケーションがだしてくれないなら、自分でアプリケーションを変更してしまいましょう。
フロントエンド監視 #
フロントエンド監視をするなら、専門の SaaS プロダクトを使うことをおすすめします。これらのプロダクトには計測のためのライブラリが備えられていて、使い方もシンプルです。もしこの方針を採用するなら、Google Analytics はおそらく最高の選択です。小規模なインフラで小さなサイトを運営しているならなおさらです。
多くの場合、フロントエンドのパフォーマンスを記録しておくのに SaaS ツールを使うことになるでしょうが、内部がどうなっているかを見ていきましょう。
Navigation Timing API
ブラウザは、Navigation Timing API という仕様に基づいた API を通じて、ページパフォーマンスのメトリクスを公開しています。この API で使用可能なメトリクスの一覧は次のとおりです。
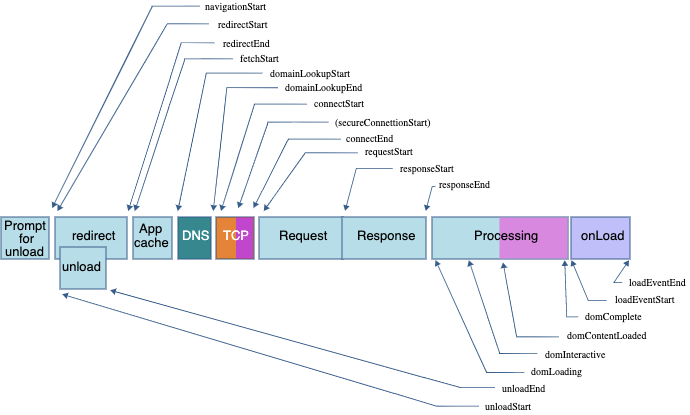
常に有益なのは以下のメトリクスです。
- navigationStart:ブラウザによってページリクエストが開始されたタイミングです。
- domLoading:DOM がコンパイルされロードが始まったタイミングです。
- domInteractive:ページが使用可能になったと考えられるタイミングです。ただし、ページのロードが終わっているとは限りません。
- domContentLoaded:すべてのスクリプトが実行されたタイミングです。
- domComplete:ページがすべて(HTML、CSS、JavaScript)のロードを終えたタイミングです。
ブラウザにはこれ以外にも User Timing API と呼ばれる、さらに細かい計測を行おうとする人向けの便利な API があります。Navigation Timing API のメトリクスは設定済みである一方、User Timing API は自分でメトリクスやイベントを作ることができます。
Speed Index
事実上の標準フロントエンドパフォーマンステストツールとして使われている WebpageTest には、興味深く便利ないくつかのメトリクスがあります。中でも最も有名なのが、あなたも聞き覚えがあるかもしれない Speed Index です。
Navigation Timing のメトリクスがブラウザによる正確な報告に基づいている一方で、Speed Index は、視覚的な観点でページがロードされ終わったのがいつかを判断するのに、秒間 10 フレームのビデオキャップを使います。ユーザの体感を完全に判断する点では、ブラウザが報告して来るメトリクスよりずっと正確です。テスト結果は Speed Index アルゴリズムによって計算され、その数値は小さいほどよいです。
シンセティック監視
Web サイトが動いているかを確認するために curl を実行したことがあるなら、それがシンセティックテストです。さらに高機能で、Web ページのパフォーマンスに特化したツールが存在しています。さらに高機能で、Web ページのパフォーマンスに特化したツールが存在しています。中でも成功しているのが WebpageTest.org です。
ここでは WebpageTest(Speed Index を作ったのも彼らです)の凝った使い方を取り上げます。それは、あなたのテスト環境に統合するということです。Web アプリケーションのパフォーマンスは、能動的かつ定期的にパフォーマンスを最適化していかないと、時間の経過と共に悪化していく傾向があります。計測していないものを改善することはできませんが、プルリクエストごとにフロントエンドのパフォーマンスへの影響が計測できたらどうでしょうか。WebpageTest をあなたの自動テスト環境で使えるようにすると、新機能のパフォーマンスへの影響をチームが考慮し、苦労して得たパフォーマンス改善の効果を失ってしまわないようにできます。
アプリケーション監視 #
この本では特定のツールについて話さないと言いましたが、例外があります。StatsD は、いろいろな状況で簡単に使うことができることから、その例外の1つです。StatsD は、コードの中にメトリクスを追加するためのツールです。Etsy によって 2011 年に作られて以来、その簡単さと柔軟性から、StatsD はモダンな監視スタックには不可欠な存在になりました。StatsD を使わないとしても、知っておくのは重要です。StatsD は元々は Graphite バックエンド用にデザインされた経緯があり、メトリクス名はドット区切り(例えば my.cool.metric)になっています。
def login():
if password_valid():
render_template('welcome.html')
else:
render_template('login_failed.html', status=403)
どのくらいの頻度でログインの成功と失敗が発生しているかを計測してみましょう。
import statsd
statsd_client = statsd.StatsClient('localhost', 8125)
def login():
statsd_client.incr('app.login.attempts')
if password_valid():
statsd_client.incr('app.login.successes')
render_template('welcome.html')
else:
statsd_client.incr('app.login.failures')
render_template('login_failed.html', status=403)
メトリクスを追加しました。ログインが何回試行されたか、ログインが何回成功したか、ログインが何回失敗したかの3つです。
StatsD は何かの処理にかかった時間を計ることもサポートしています。
import statsd
statsd_client = statsd.StatsClient('localhost', 8125)
def login():
login_timer = statsd_client.timer('app.login.time')
login_timer.start()
if password_valid():
render_template('welcome.html')
else:
render_template('login_failed.html', status=403)
login_timer.stop()
login_timer.send()
この例では関数の実行時間を記録、つまり事実上のログイン時間を計るタイマを設定しています。ログイン処理に普通はどのくらいの時間がかかっているかが分かれば、「ログインがいつもより遅いんじゃない?」という質問に、直感で判断したり肩をすくめて分からないと言う代わりに、すぐに答えられます。
health エンドポイントパターン
この考え方はしばらく前からあるものの、このパターンに誰も公式な名前をつけていませんでした。私はこれを「/health エンドポイントパターン」と呼ぶことにしました。オンラインで見つかる記事では、カナリアエンドポイントと呼んでいるものや、単にステータスエンドポイントとしているものもあります。
呼び方はともかく、考え方は単純です。アプリケーションの健全性を伝えるアプリケーション内の HTTP エンドポイントであり、アプリケーションについての基本的な情報(デプロイされたバージョンや依存性のステータスなど)を含む場合もあります。エンドポイントの裏側には、アプリケーションの健全性と状態についての情報を取得する独立したコードが存在しています。この実装はシンプルなものから非常に複雑なものまでいろいろあります。
from django.db import connection as sql_connection
from django.http import JsonResponse
import redis
def check_sql():
try:
# SQL データベースに接続し1行を select
with sql_connection.cursor() as cursor:
cursor.execute('SELECT 1 FROM table_name')
cursor.fetchone()
return {'okay': True}
except Exception e:
return {'okay': False, 'error': e}
def check_redis():
try:
# Redis データベースに接続しキー1つを取得
redis_connection = redis.StrictRedis()
result = redis_connection.get('test-key')
# そのキーの値を既知の値と比較
if result == 'some-value':
return {'okay': True}
else:
return {'okay': False, 'error': 'Test value not found'}
except Exception e:
return {'okay': False, 'error': e}
def health():
if all(check_sql().get('okay'), check_redis().get('okay')):
return JsonResponse({'status': 200}, status=200)
else:
return JsonResponse(
{
'mysql_okay': check_sql().get('okay'),
'mysql_error': check_sql().get('error', None),
'redis_okay': check_redis().get('okay'),
'redis_error': check_redis().get('error', None),
},
status=503
)
この例では MySQL と Redis の2つのチェックを health() 関数から呼び出しています。
サービスが他のサービスに依存しているなら、このヘルスチェックの仕組みをそのチェックにも使えます。例えばサービスが外部の API に強く依存しているならそのチェックを行うこともできます。
このパターンを繰り返していくとヘルスチェックは最初よりもずっと複雑になります。分散マイクロサービスアーキテクチャで、各マイクロサービスにこのパターンを広く適用すると、最終的には自分自身が正常かどうかを各サービスが把握していることになります。つまり、環境全体を自動的にテストし続けているのと同じことになります。
/health エンドポイントが複雑すぎると、エンドポイントが問題があると知らせた時のデバッグが難しくなってしまったり、チェックすべき依存性が多いせいでエンドポイントが不必要に敏感になってしまったりすることに気づいたチームもあることに注意しましょう。高度に相互接続されたサービスがたくさんのヘルスチェックを行なっているため、問題がどこにあるのか判断するのが難しくなってしまうという状況は容易に想像がつくでしょう。
エンドポイントがアプリケーション内のルーティングの1つであるべきか、全く別のアプリケーションであるべきかも、よくある質問の1つです。監視の仕組みがアプリケーションと一緒に提供されるよう、エンドポイントはアプリケーション内にあるべきです。そうでなければ、このパターンの意味がありません。
このパターンを使うときに見逃されがちな重要な点があります。それは、正しい HTTP ステータスコードを使うことです。すべてが正常なら、HTTP200 を返しましょう。正常でないなら、HTTP200 以外(HTTP503 Service Unavailable がここではよいでしょう)を返しましょう。正しい HTTP ステータスコードを使うことで、応答に含まれる文字列をパースしなくても、正常動作しているかどうかを判断するのが簡単になります。
セキュリティについての懸念はあるか
このパターンに対して、セキュリティ上の懸念があるという異論を聞いたことがあります。確かにユーザからこのエンドポイントにはアクセスして欲しくないでしょう。この問題は、Web サーバでアクセス制限をかけて、特定のソースアドレスだけがこのエンドポイントにアクセスできるようにし、それ以外からのアクセスをリダイレクトすれば解決できます。
監視アセスメントの例題 #
この本で学んだことすべてをまとめて適用するフィクションの例題を見てみましょう。
監視アセスメントを実施するのは、何を監視すべきか、なぜ監視すべきかをシステマチックに判断する良い方法です。その目的は、アプリケーションとその裏にあるインフラをより明確に理解することです。監視アセスメント自体は徹底的あるいは完璧とは言えませんが、何が問題で何が問題でないのかを考える出発点になります。
1. ビジネス監視
最初にビジネス KPI を特定します。Tater.ly のミッションは、フレンチフライの熱狂的ファンたちが、最高のフレンチフライを見つけられるようにすることです。ユーザは、レストランを探したり、そのレストランのフレンチフライをレビューを見たり、投稿します。レストランは自店のページを持つことができ、さらに広告費を払うことで検索結果の1番上に広告を出すことができます。
以下を KPI とすることに決めました。
- レストランのレビュー数
- アクティブなレストラン(オーナーがログインしている)の数
- ユーザ数
- アクティブユーザ数
- 検索実行数
- レビュー投稿数
- 広告購入数
- 上記の各項目の変化の方向と変化率
2. フロントエンド監視
監視すべきことはただ1つです。以下を監視します。
- ユーザ視点でのページロード時間
3. アプリケーションとサーバの監視
決定にあたり必要な情報がインフラのアーキテクチャです。最前列に CDN が配置されていて、その後ろにロードバランサが2台、さらにその背後に Web サーバが4台、そしてその後ろに2台(プライマリ・レプリカ構成)の PostgreSQL データベースサーバとセッションストレージの Redis サーバが1台あるとします。自前のデータセンターではなくホスティングプロバイダを使用しているため、ハードウェアやネットワークの管理についてはあまり気にしなくてよい環境だとします。
思いつくメトリクスやログ以下です。
- メトリクス
- ページロード時間
- ユーザログイン:成功数、失敗数、実行時間、1日のアクティブユーザ数、1週間のアクティブユーザ数
- 検索:検索実行数、レイテンシ
- (アプリケーションから見た)データベースのクエリレイテンシ
- (データベースサーバから見た)データベースの秒間トランザクション数
- (Redis サーバから見た)Redis の秒間トランザクション数
- CDN:ヒット・ミス比率、オリジンに対するレイテンシ
- HAProxy:秒間リクエスト数、利用可能・不能なバックエンドの数、フロントエンドとバックエンドでの HTTP レスポンスコード
- Apache:秒間リクエスト数、HTTP レスポンスコード
- OS:CPU 使用率、メモリ使用率、ネットワークスループット、ディスク IOPS と空き容量
- ログ
- ユーザログイン:ユーザ ID、コンテキスト(成功、失敗、失敗の理由)
- Django:例外、トレースバック
- 使用しているすべてのサーバサイドデーモンのサービスログ:Apache、PostgreSQL、Redis、HAProxy
さらに SSL 証明書の期限切れについても監視が行えそうです。
4. セキュリティ監視
Tater.ly では特にコンプライアンスや業界規制がないためセキュリティ監視は単純です。
- SSH ログインの試行と失敗
- syslog のログ
- auditd のログ
5. アラート
最後にアラートを設定する必要があります。これまで特定済みのメトリクスとログを見るに、以下のようなアラートが必要だと考えました。
- ページロード時間の増加
- Redis、Apache、HAProxy でのエラー率やレイテンシの増加
- 検索、レビュー投稿、ユーザログインといった、アプリケーションの特定のアクションのエラー率やレイテンシの増加
- PostgreSQL クエリのレイテンシの増加
6. 手順書
最後にこれまでまとめた知識を同僚たちが活用できるよう、新しく発見した情報を含めて手順書に書き記すのを忘れないでください。